parse_dates : boolean or list of ints or names or list of lists or dict, default False
boolean. If True -> try parsing the index.
list of ints or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3 each as a separate date column.
list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and parse as a single date column.
dict, e.g. {‘foo' : [1, 3]} -> parse columns 1, 3 as date and call result ‘foo'
If a column or index contains an unparseable date, the entire column or index will be returned unaltered as an object data
type. For non-standard datetime parsing, use pd.to_datetime after pd.read_csv
中文解释:
boolean. True -> 解析索引
list of ints or names. e.g. If [1, 2, 3] -> 解析1,2,3列的值作为独立的日期列;
list of lists. e.g. If [[1, 3]] -> 合并1,3列作为一个日期列使用
dict, e.g. {‘foo' : [1, 3]} -> 将1,3列合并,并给合并后的列起名为"foo"
补充:解决Pandas的to_excel()写入不同Sheet,而不会被重写
在使用Pandas的to_excel()方法写入数据时,当我们想将多个数据写入一个Excel表的不同DataFrame中,虽然能够指定sheet_name参数,但是会重写整个Excel之后才会存储。
现在我有三个DataFrame,分别是大众某车型的配置、外观和内饰数据。现在我想要将这三个DF存入一张表的不同sheet中
>>> df1
220V车载电源 A/C开关 ACC Autohold Aux BMBS爆胎监测与安全控制系统 CD机 CarPlay
0 0 0 0 0 0 0 1
>>> df2
A柱 B柱 C柱 保险杠 倒车灯 倒车镜尺寸 前后灯 前脸 前风窗玻璃 后视镜尺寸
0 0 0 0 0 0 0 0 0 0
>>> df3
HUD抬头数字显示 中控台 中控锁 中控面板 中间扶手 仪表盘 儿童安全座椅接口 全景天窗 分辨率 后排出风口
0 0 4 5 0 0 13 0 0 0
一般情况下:
df1.to_excel("大众.xlsx",sheet_name="配置")
df2.to_excel("大众.xlsx",sheet_name="外观")
df3.to_excel("大众.xlsx",sheet_name="内饰")
可是结果中:
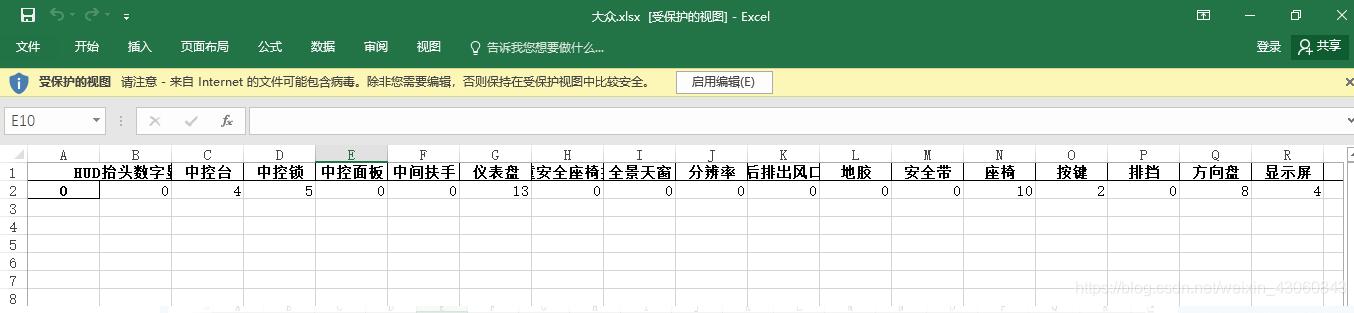
只有最后一个存储的内饰数据,并不符合我们的需求。
解决方法:
writer = pd.ExcelWriter('大众.xlsx')
df1.to_excel(writer,"配置")
df2.to_excel(writer,"外观")
df3.to_excel(writer,"内饰")
writer.save()
结果:
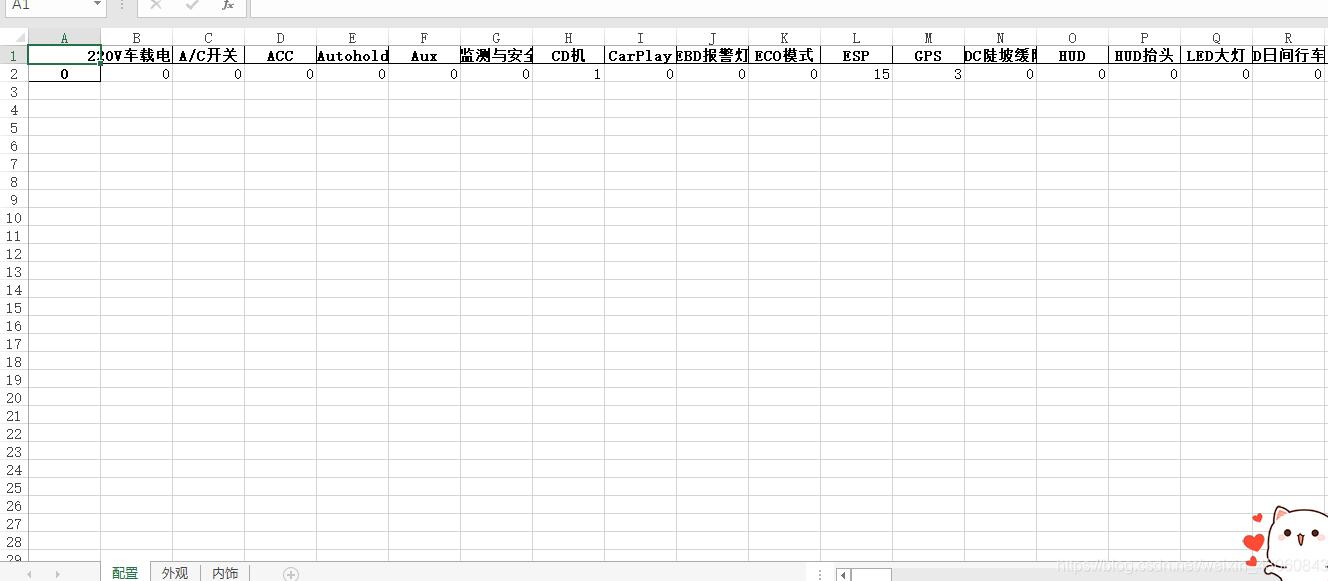
实现插入相同Excel表中不同Sheet_name!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- pandas.read_csv参数详解(小结)
- python读写数据读写csv文件(pandas用法)
- Pandas操作CSV文件的读写实现方法
- pandas中read_csv、rolling、expanding用法详解


 咨 询 客 服
咨 询 客 服