#!/usr/bin/env python
# -*- coding:utf-8 -*-
# datetime:2021/3/17 12:12
# software: PyCharm
# version: python 3.9.2
def changePdfToText(filePath):
"""
解析pdf 文本,保存到同名txt文件中
param:
filePath: 需要读取的pdf文档的目录
introduced module:
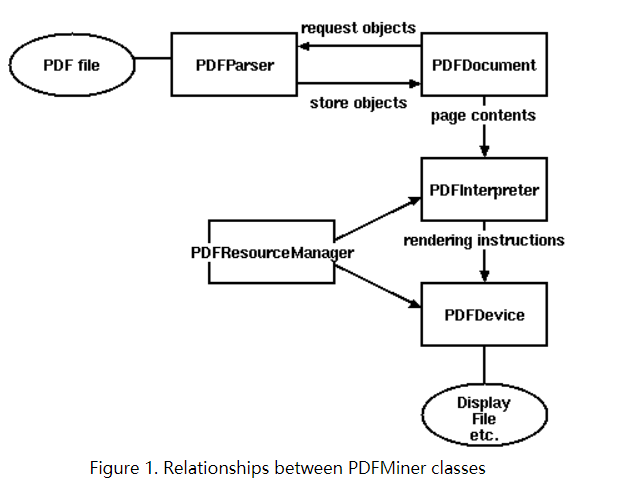
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfdocument import PDFDocument, PDFTextExtractionNotAllowed
import os.path
"""
file = open(filePath, 'rb') # 以二进制读模式打开
# 用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument(praser, '') # praser :上面创建的pdf文档分析器 ,第二个参数是密码,设置为空就好了
# 连接分析器 与文档对象
praser.set_document(doc)
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
result = [] # 内容列表
# 循环遍历列表,每次处理一个page的内容
for page in PDFPage.create_pages(doc):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
result.append(x.get_text())
fileNames = os.path.splitext(filePath) # 分割
# 以追加的方式打开文件
with open(fileNames[0] + '.txt', 'a', encoding="utf-8") as f:
results = x.get_text()
# print(results) 这个句可以取消注释就可以在控制台将所有内容输出了
f.write(results) # 写入文件
# 调用示例 :
# path = u'E:\\1.pdf'
# changePdfToText(path)
from PyPDF2 import PdfFileReader
# 定义获取pdf内容的方法
def getPdfContent(filename):
# 获取PdfFileReader对象
pdf = PdfFileReader(open(filename, "rb"))
content = "" #content是输出文本
for i in range(0,pdf.getNumPages()): #遍历每一页
pageObj = pdf.getPage(i)
try:
extractedText = pageObj.extractText()#导出每一页的内容,如果当前页有图片的话就跳过
content += extractedText + "\n"
except BaseException:
pass
return content.encode("ascii", "ignore")
# 将获取的内容写入txt文件
with open("test.txt","w") as f:
count=0 #count的作用是限制每一行的文字个数,本人设置的是十行
#将获取的文本变成字符串并用空白隔开
for item in str(getPdfContent("test.pdf")).split(" "):
# 如果当前文字以句号结尾就换行
if item[-1]==".":
f.write(item+"\n")
count=0
else:
f.write(item+" ")
count +=1
# 如果写了十个字就换行
if count==10:
f.write("\n")
# 重置count
count = 0
到此这篇关于python读取pdf格式文档的文章就介绍到这了,更多相关python读取pdf文档内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!


 咨 询 客 服
咨 询 客 服