import torch
import matplotlib.pyplot as plt
# 构建数据集
x_data= torch.Tensor([[1.0],[2.0],[3.0],[4.0],[5.0],[6.0]])
y_data= torch.Tensor([[2.0],[4.0],[6.0],[8.0],[10.0],[12.0]])
#定义模型
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear= torch.nn.Linear(1,1) #表示输入输出都只有一层,相当于前向传播中的函数模型,因为我们一般都不知道函数是什么形式的
def forward(self, x):
y_pred= self.linear(x)
return y_pred
model= LinearModel()
# 使用均方误差作为损失函数
criterion= torch.nn.MSELoss(size_average= False)
#使用梯度下降作为优化SGD
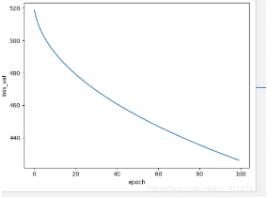
# 从下面几种优化器的生成结果图像可以看出,SGD和ASGD效果最好,因为他们的图像收敛速度最快
optimizer= torch.optim.SGD(model.parameters(),lr=0.01)
# ASGD
# optimizer= torch.optim.ASGD(model.parameters(),lr=0.01)
# optimizer= torch.optim.Adagrad(model.parameters(), lr= 0.01)
# optimizer= torch.optim.RMSprop(model.parameters(), lr= 0.01)
# optimizer= torch.optim.Adamax(model.parameters(),lr= 0.01)
# 训练
epoch_list=[]
loss_list=[]
for epoch in range(100):
y_pred= model(x_data)
loss= criterion(y_pred, y_data)
epoch_list.append(epoch)
loss_list.append(loss.item())
print(epoch, loss.item())
optimizer.zero_grad() #梯度归零
loss.backward() #反向传播
optimizer.step() #更新参数
print("w= ", model.linear.weight.item())
print("b= ",model.linear.bias.item())
x_test= torch.Tensor([[7.0]])
y_test= model(x_test)
print("y_pred= ",y_test.data)
plt.plot(epoch_list, loss_list)
plt.xlabel("epoch")
plt.ylabel("loss_val")
plt.show()


 咨 询 客 服
咨 询 客 服