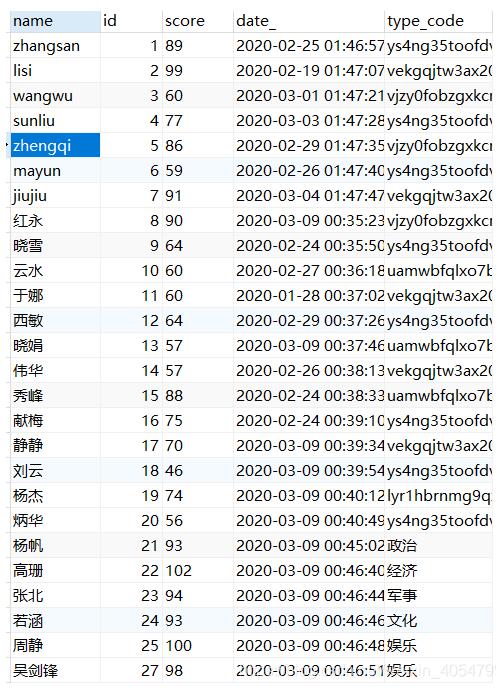
数据库中有一字段type_code,有中文类型和中文类型编码,现在对type_code字段的数据进行统计处理,编码对应的字典如下:
{'ys4ng35toofdviy9ce0pn1uxw2x7trjb':'娱乐',
'vekgqjtw3ax20udsniycjv1hdsa7t4oz':'经济',
'vjzy0fobzgxkcnlbrsduhp47f8pxcoaj':'军事',
'uamwbfqlxo7bu0warx6vkhefigkhtoz3':'政治',
'lyr1hbrnmg9qzvwuzlk5fas7v628jiqx':'文化',
}
其中数据库的32位随机编码生成程序如下:
string.ascii_letters 对应字母(包括大小写), string.digits(对应数字) ,string.punctuation(对应特殊字符)
import string
import random
def get_code():
return ''.join(random.sample(string.ascii_letters + string.digits + string.punctuation, 32))
print(get_code())
def get_code1():
return ''.join(random.sample(string.ascii_letters + string.digits, 32))
testresult= get_code1()
print(testresult.lower())
print(type(testresult))
结果:
)@+t37/b|UQ[K;!spj(>%r9"PokwTe=
igwle98kgqtcprke7byvq12xnhucmz4v
class 'str'>
cur.fetchall:
import pymysql
import pandas as pd
conn = pymysql.Connect(host="127.0.0.1",port=3306,user="root",password="123456",charset="utf8",db="sql_prac")
cur = conn.cursor()
print("连接成功")
sql = "SELECT type_code,count(1) as num FROM test GROUP BY type_code ORDER BY num desc"
cur.execute(sql)
res = cur.fetchall()
print(res)
(('ys4ng35toofdviy9ce0pn1uxw2x7trjb', 8), ('vekgqjtw3ax20udsniycjv1hdsa7t4oz', 5), ('vjzy0fobzgxkcnlbrsduhp47f8pxcoaj', 3), ('uamwbfqlxo7bu0warx6vkhefigkhtoz3', 3), ('娱乐', 2), ('lyr1hbrnmg9qzvwuzlk5fas7v628jiqx', 1), ('政治', 1), ('经济', 1), ('军事', 1), ('文化', 1))
res = pd.DataFrame(list(res), columns=['name','value'])
print(res)

dicts = {'ys4ng35toofdviy9ce0pn1uxw2x7trjb':'娱乐',
'vekgqjtw3ax20udsniycjv1hdsa7t4oz':'经济',
'vjzy0fobzgxkcnlbrsduhp47f8pxcoaj':'军事',
'uamwbfqlxo7bu0warx6vkhefigkhtoz3':'政治',
'lyr1hbrnmg9qzvwuzlk5fas7v628jiqx':'文化',
}
res['name'] = res['name'].map(lambda x:dicts[x] if x in dicts else x)
print(res)
name value
0 娱乐 8
1 经济 5
2 军事 3
3 政治 3
4 娱乐 2
5 文化 1
6 政治 1
7 经济 1
8 军事 1
9 文化 1
#分组统计
result = res.groupby(['name']).sum().reset_index()
print(result)
name value
0 军事 4
1 娱乐 10
2 政治 4
3 文化 2
4 经济 6
#排序
result = result.sort_values(['value'], ascending=False)
name value
1 娱乐 10
4 经济 6
0 军事 4
2 政治 4
3 文化 2
#输出为list,前端需要的数据格式
data_dict = result.to_dict(orient='records')
print(data_dict)
[{'name': '娱乐', 'value': 10}, {'name': '经济', 'value': 6}, {'name': '军事', 'value': 4}, {'name': '政治', 'value': 4}, {'name': '文化', 'value': 2}]
cur.fetchone
先测试SQL:
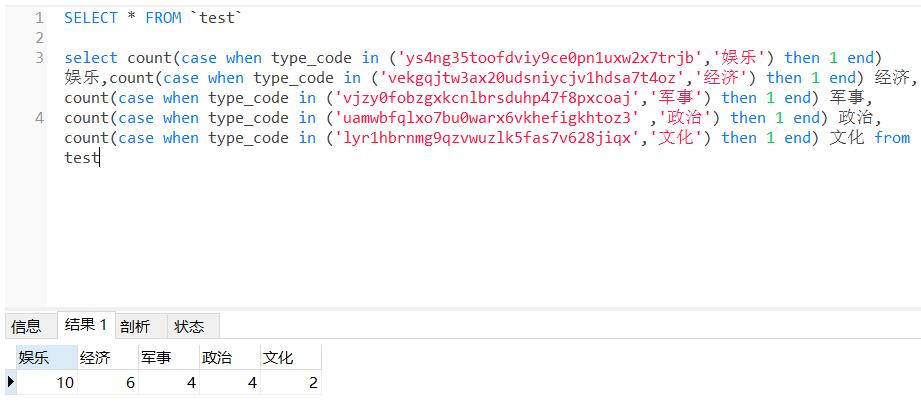
代码:
import pymysql
import pandas as pd
conn = pymysql.Connect(host="127.0.0.1",port=3306,user="root",password="123456",charset="utf8",db="sql_prac")
cur = conn.cursor()
print("连接成功")
sql = "select count(case when type_code in ('ys4ng35toofdviy9ce0pn1uxw2x7trjb','娱乐') then 1 end) 娱乐," \
"count(case when type_code in ('vekgqjtw3ax20udsniycjv1hdsa7t4oz','经济') then 1 end) 经济," \
"count(case when type_code in ('vjzy0fobzgxkcnlbrsduhp47f8pxcoaj','军事') then 1 end) 军事," \
"count(case when type_code in ('uamwbfqlxo7bu0warx6vkhefigkhtoz3' ,'政治') then 1 end) 政治," \
"count(case when type_code in ('lyr1hbrnmg9qzvwuzlk5fas7v628jiqx','文化') then 1 end) 文化 from test"
cur.execute(sql)
res = cur.fetchone()
print(res)
返回结果为元组:
(10, 6, 4, 4, 2)
data = [
{"name": "娱乐", "value": res[0]},
{"name": "经济", "value": res[1]},
{"name": "军事", "value": res[2]},
{"name": "政治", "value": res[3]},
{"name": "文化", "value": res[4]}
]
result = sorted(data, key=lambda x: x['value'], reverse=True)
print(result)
结果和 cur.fetchall返回的结果经过处理后,结果是一样的:
[{'name': '娱乐', 'value': 10}, {'name': '经济', 'value': 6}, {'name': '军事', 'value': 4}, {'name': '政治', 'value': 4}, {'name': '文化', 'value': 2}]
补充:今天做测试,用django.db 的connection来执行一个非常简单的查询语句:
sql_str = 'select col_1 from table_1 where criteria = 1'
cursor = connection.cursor()
cursor.execute(sql_str)
fetchall = cursor.fetchall()
fetchall的值是这样的:
(('101',), ('102',), ('103',),('104',))
上网搜索了一下资料:
首先fetchone()函数它的返回值是单个的元组,也就是一行记录,如果没有结果,那就会返回null
其次是fetchall()函数,它的返回值是多个元组,即返回多个行记录,如果没有结果,返回的是()
举个例子:cursor是我们连接数据库的实例
fetchone()的使用:
cursor.execute(select username,password,nickname from user where id='%s' %(input)
result=cursor.fetchone(); 此时我们可以通过result[0],result[1],result[2]得到username,password,nickname
fetchall()的使用:
cursor.execute(select * from user)
result=cursor.fetchall();此时select得到的可能是多行记录,那么我们通过fetchall得到的就是多行记录,是一个二维元组
((username1,password1,nickname1),(username2,password2,nickname2),(username3,password3,nickname))
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- Python 统计数据集标签的类别及数目操作
- Python统计可散列的对象之容器Counter详解
- Python 统计列表中重复元素的个数并返回其索引值的实现方法
- Python实战之单词打卡统计
- python自动统计zabbix系统监控覆盖率的示例代码
- python 统计代码耗时的几种方法分享
- Python统计列表元素出现次数的方法示例
- python统计RGB图片某像素的个数案例
- Python jieba 中文分词与词频统计的操作
- 利用Python3实现统计大量单词中各字母出现的次数和频率的方法
- 使用Python 统计文件夹内所有pdf页数的小工具
- python 统计list中各个元素出现的次数的几种方法
- python调用百度AI接口实现人流量统计
- Python代码覆盖率统计工具coverage.py用法详解
- python 爬虫基本使用——统计杭电oj题目正确率并排序
- 利用python汇总统计多张Excel
- python统计mysql数据量变化并调用接口告警的示例代码
- 用python实现监控视频人数统计


 咨 询 客 服
咨 询 客 服