我们使用的是IMDB数据集,它包含来自互联网电影数据库(IMDB)的50000条严重两极分化的评论。为了避免模型过拟合只记住训练数据,我们将数据集分为用于训练的25000条评论与用于测试的25000条评论,训练集和测试集都包含50%的正面评论和50%的负面评论。
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
1
填充列表,使其具有相同的长度,然后将列表转化为(samples, word_index)的2D形状的整数张量。对列表进行one-hot编码,将其转化为0和1组成的向量。
这里的Dense层实现了如下的张量计算,传入Dense层的参数16表示隐藏单元的个数,同时也表示这个层输出的数据的维度数量。隐藏单元越多,网络越能够学习到更加复杂的表示,但是网络计算的代价就越高。
将训练数据分出一小部分作为校验数据,同时将512个样本作为一批量处理,并进行20轮的训练,同时出入validation_data来监控校验样本上的损失和计算精度。
字典中包含4个条目,对应训练过程和校验过程的指标,其中loss是训练过程中损失指标,accuracy是训练过程的准确性指标,而val_loss是校验过程的损失指标,val_accuracy是校验过程的准确性指标。
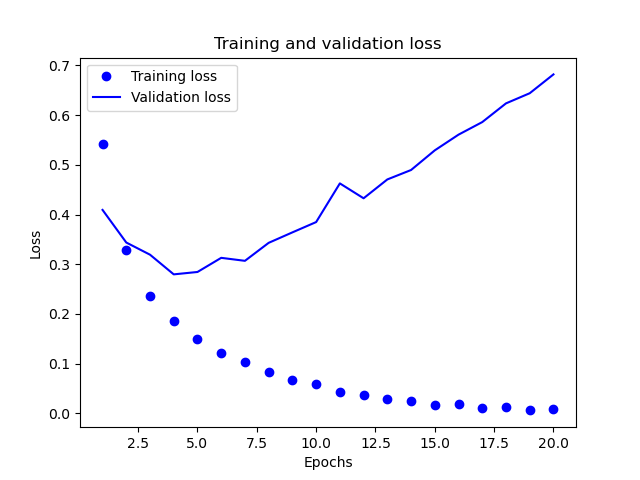
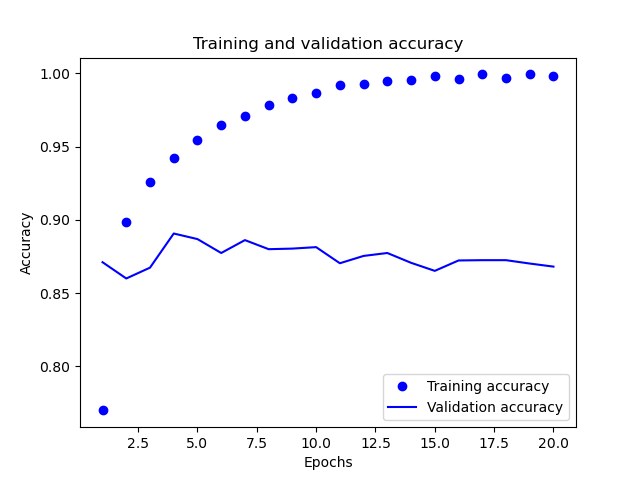
通过对训练和校验指标的分析,可以看到训练的损失每轮都在降低,训练的精度每轮都在提升。但是校验损失和校验精度基本上在第4轮左右达到最佳值。为了防止这种过拟合的情况,我们可以在第四轮完成之后直接停止训练。
到此这篇关于机器深度学习之电影的二分类情感问题的文章就介绍到这了,更多相关深度学习内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!


 咨 询 客 服
咨 询 客 服