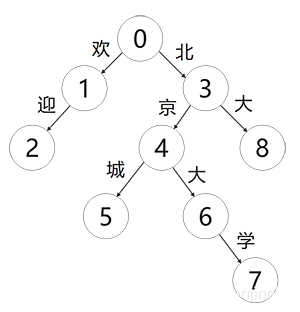
| 词语 | 路径 |
| 欢迎 | 0-1-2 |
| 北大 | 0-3-8 |
| 北京城 | 0-3-4-5 |
| 北京大学 | 0-3-4-6-7 |
至于字典树的实现,相信只要认真学过数据结构的读者,都能手到擒来,这里不在赘述。因为HanLP库已经提供了多种字典树。
认识DoubleArrayTrieSegment类之前,我们需要了解双数组字典书的概念。
我们都知道,在树中遍历查找之时,我们一般用二分查找,假如某一个树的节点有N个节点,那么其复杂度就为O(logN),这样查找起来一条一条树的遍历会非常的慢,所以就诞生了双数组字典树的概念。
双数组字典树(DAT)是一种状态转移复杂度为常数的数据结构。那么什么是状态呢?从确定有限状态自动机(DFA)的角度来讲,每个节点都是一个状态,状态表示当前已查询到的前缀。
从父节点到子节点的移动过程可以看作一次状态转移。在按照某个字符进行状态转移前,我们会向父节点询问该字符与子节点的映射关系(也就是一条路径一条边)。如果父节点有满足条件的边,则状态转移到子节点;否则立即失败,查询不到。当成功完成了全部转移时,我们就拿到了最后一个状态,询问该状态是否时最终状态。如果是,就查询到该词汇,否则该单词不存在于字典中。
比如我们查询首图的“北京大学”,状态开始为0,查询到北时状态为3,查询到京时状态为4,查询到大时状态为6,查询到学时状态为7,最后判断7是否还有子节点,如果没有匹配该词汇,如果有该词汇不在字典中。比如查询“北京大”就不在词汇中。
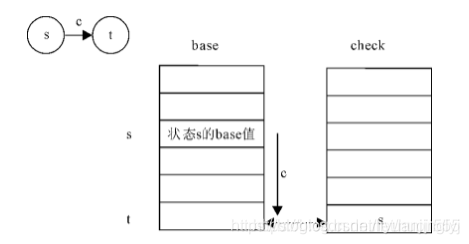
而双数组字典由base与check两个数组组成,其中base数组即节点,也是状态,分为空闲状态与占用状态,check数组为每个元素表示某个状态的前驱状态。具体公式如下:
base[s] + c = t check[t] = s
base树组中的s代表当前状态的下标,t代表转移状态的下标,c代表输入字符的数值
base[s] + c = t //表示一次状态转移
由于转移后状态下标为t,且父子关系是唯一的,所以可通过检验当前元素的前驱状态确定转移是否成功
check[t] = s //检验状态转移是否成功
这种算法相对于传统的Trie树二分查找的优点是,只需要一个加法一次比较即可完成一次状态转移,只花费了常数时间,下面给出了双数组Tree树的原理图(注意观察状态转移的过程)
了解了双数组字典树的原理,我们就可以来学习DoubleArrayTrieSegment,DoubleArrayTrieSegment分词器是对DAT(双数组字典树)最长匹配的封装,默认加载hanlp.properites中CoreDictionaryPath指定的词典。
对应的python代码如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=False#分词结果不显示词性
segment=DoubleArrayTrieSegment()
print(segment.seg("在来到这个世界之前,一起都很Happy"))
运行之后,得到如下图所示的结果:

当然,这是HanLP提供给我们的默认词典,如果想加载自己的词典,或者前文提到的其他开源的词典库,可以替换代码如下所示:
DoubleArrayTrieSegment(["词典1","词典2"])
但是不知道读者注意到了没有,上面的英文happy,它给我们拆成了单个的字母,但其实这是一个整体,如果这里替换成数字,也是一个一个数字,那么如何不让其拆开呢?
我们来看一段代码:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=True
segment=DoubleArrayTrieSegment()
segment.enablePartOfSpeechTagging(True)
print(segment.seg("在来到这个世界之前,一起都很Happy"))
enablePartOfSpeechTagging函数的意思是激活数字与英文识别,同时我们把ShowTermNature改为True,观察其输出的结果:

这里与我们前面自己写的算法输出一模一样,有分开的词汇以及词汇的标记属性。
虽然双数组字典树能遍历大量的数据,但是如果数据比较长的,这些长的词汇又比较多的话,比如“受命于天,既寿永昌”算一个词汇,那么其处理起来时间复杂度依旧非常耗时。所以,我们就需要使用ACDAT进行遍历。
这里博主不讲解其原理,因为太长篇幅有限,感兴趣的可以专门学习树结构的处理。读者只需要知道其原理,什么时候用双数组遍历,什么时候用ACDAT遍历就行。而HanLP封装的ACDAT的实现类是AhoCorasickDoubleArrayTrieSegment。
下面,我们来实现AhoCorasickDoubleArrayTrieSegment,代码如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature = False
segment = JClass("com.hankcs.hanlp.seg.Other.AhoCorasickDoubleArrayTrieSegment")()
print(segment.seg("在来到这个世界之前,一起都很井然有序"))
运行之后,效果如下:

需要注意的是,python的HanLP虽然提供了AhoCorasickDoubleArrayTrieSegment类,但是读者可以试试,替换后运行会报错,控制台会提示该类没有seg函数。而HanLP库又是基于Java开发的,所以在实际的项目中,尽量使用JClass加载Java类进行实战,因为python的HanLP库运行速度比Java慢一倍,但python的好处是相对简单,可以调用其他程序的类,所以速度这方面只要python引用Java类进行调用,其实速度一样。
到此这篇关于python自然语言处理之字典树知识总结的文章就介绍到这了,更多相关python字典树内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!

 咨 询 客 服
咨 询 客 服