一、前言
本文使用的是 kaggle 猫狗大战的数据集:https://www.kaggle.com/c/dogs-vs-cats/data
训练集中有 25000 张图像,测试集中有 12500 张图像。作为简单示例,我们用不了那么多图像,随便抽取一小部分猫狗图像到一个文件夹里即可。

通过使用更大、更复杂的模型,可以获得更高的准确率,预训练模型是一个很好的选择,我们可以直接使用预训练模型来完成分类任务,因为预训练模型通常已经在大型的数据集上进行过训练,通常用于完成大型的图像分类任务。
tf.keras.applications中有一些预定义好的经典卷积神经网络结构(Application应用),如下所示:
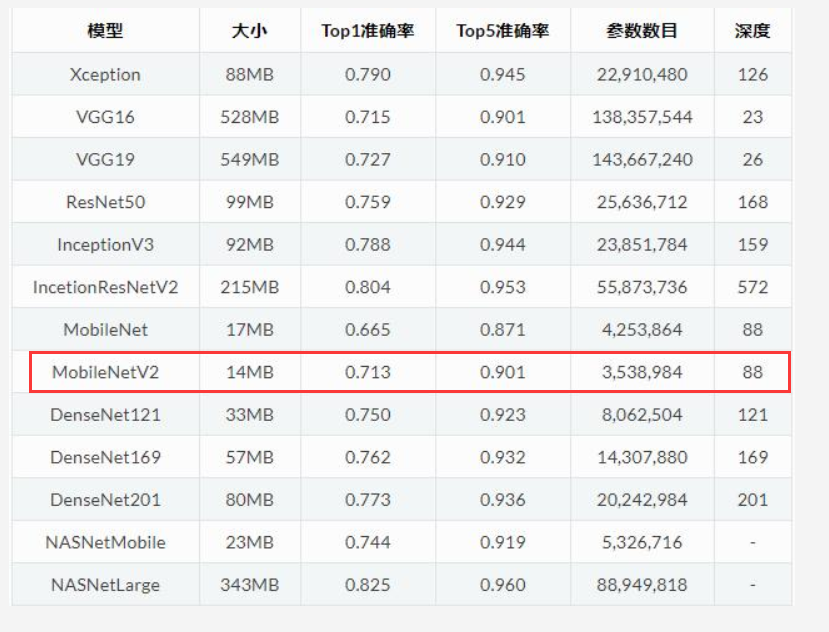
我们可以直接调用这些经典的卷积神经网络结构(甚至载入预训练的参数),而无需手动来构建网络结构。
例如,本文将要用到的模型是由谷歌开发的 MobileNetV2 网络结构,该模型已经在 ImageNet 数据集上进行过预训练,共含有 1.4M 张图像,而且学习了常见的 1000 种物体的基本特征,因此,该模型具有强大的特征提取能力。
model = tf.keras.applications.MobileNetV2()
当执行以上代码时,TensorFlow会自动从网络上下载 MobileNetV2 网络结构,运行代码后需要等待一会会儿~~。MobileNetV2模型的速度很快,而且耗费资源也不是很多。
二、k-means聚类
k-means聚类算法以 k 为参数,把 n 个对象分成 k 个簇,使簇内具有较高的相似度,而簇间的相似度较低。其处理过程如下:
- 随机选择 k 个点作为初始的聚类中心
- 对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇。
- 对每个簇,计算所有点的均值作为新的聚类中心。
- 重复步骤2、3直到聚类中心不再发生改变
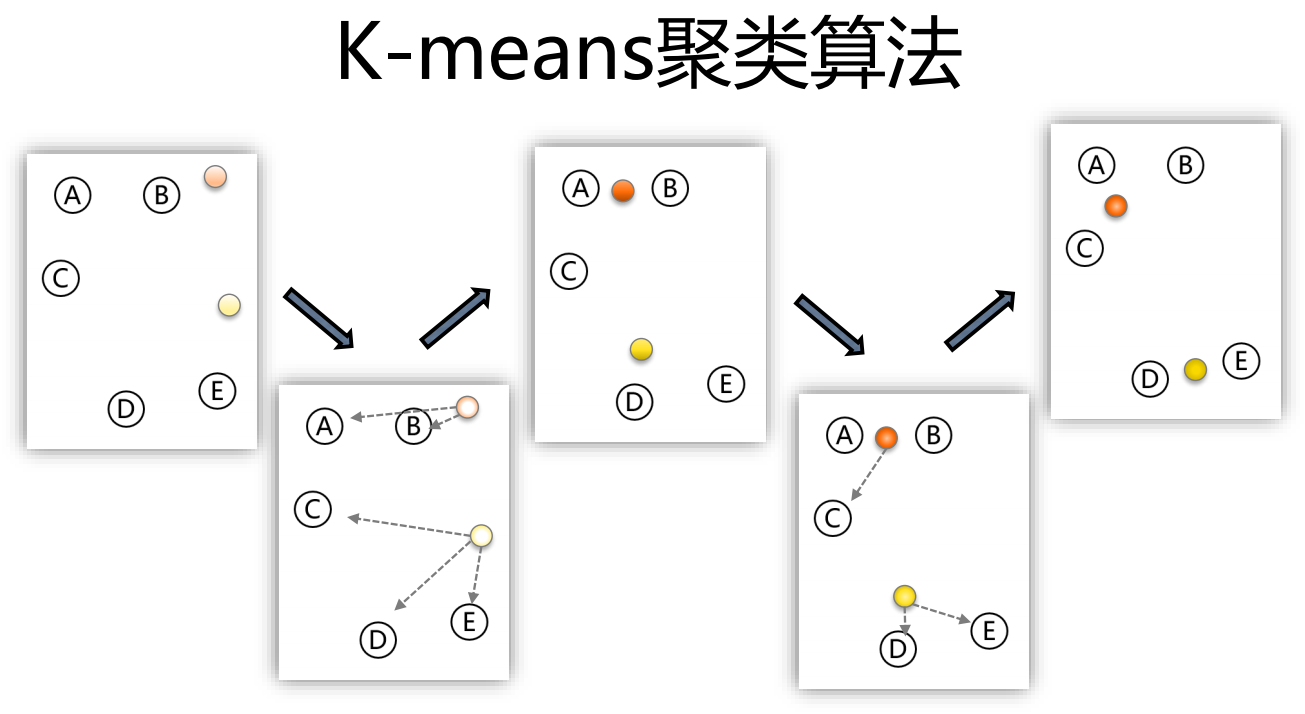
k-means的算法原理比较非常简洁、易于理解,但是这里面有个问题需要解决:
如何确定 k 值?
- 在 k-means 算法实现过程中,首先面临的问题就是如何确定好 K 值。因为在实际应用中,我们也不知道这些数据到底会有多少个类别,或者分为多少个类别会比较好,所以在选择 K 值的时候会比较困难,只能根据经验预设一个数值。
- 比较常用的一个方法:肘部法。就是去循环尝试 K 值,计算在不同的 K 值情况下,所有数据的损失,即用每一个数据点到中心点的距离之和计算平均距离。可以想到,当 K=1 的时候,这个距离和肯定是最大的;当 K=m 的时候,每个点也是自己的中心点,这个时候全局的距离和是0,平均距离也是0,当然我们不可能设置成K=m。
- 而在逐渐加大 K 的过程中,会有一个点,使这个平均距离发生急剧的变化,如果把这个距离与 K 的关系画出来,就可以看到一个拐点,也就是我们说的手肘。
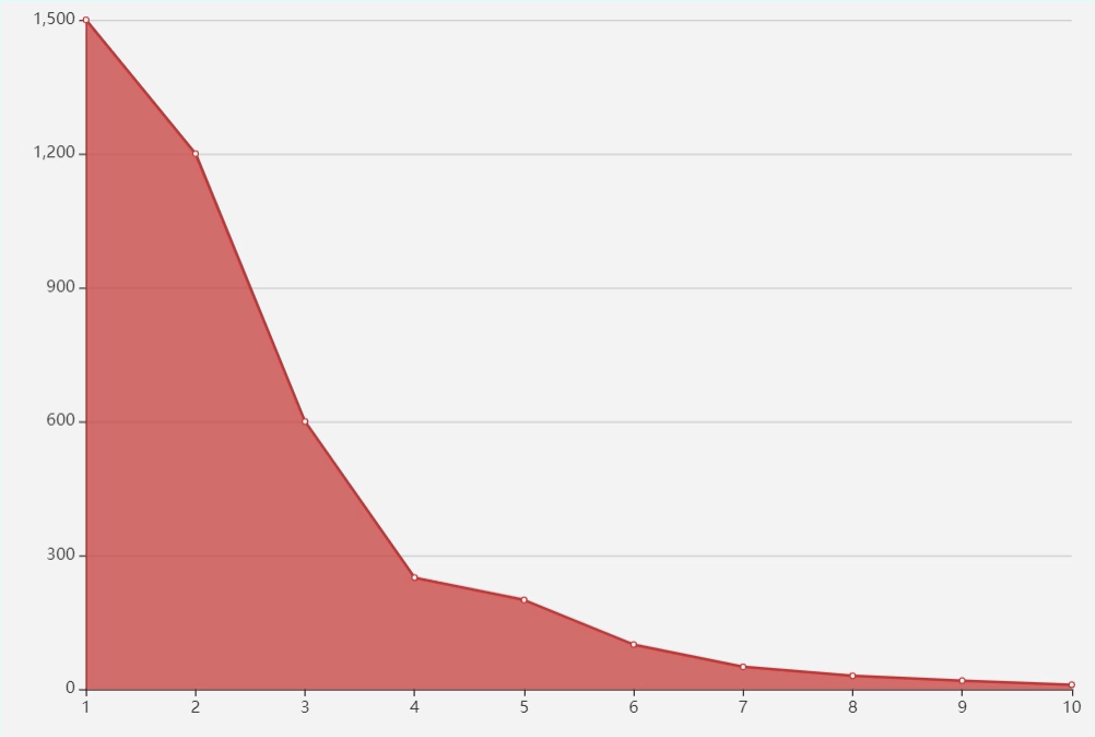
要确定 K 值确实是一项比较费时费力的事情,但是也是 K-Means 聚类算法中必须要做好的工作。
三、图像分类
现在进入正题,实现我们的猫狗图像分类。
导入需要的依赖库
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import cv2 as cv
import os, shutil
from pathlib import Path
获取 animals 文件夹下所有 jpg 猫狗图像
# 获得该文件夹下所有jpg图片路径
p = Path(r"C:\Users\Administrator\DeepLearning\animals")
files = list(p.glob("**/*.jpg"))
opencv读取图像,并将图像大小 resize 为(224,224),以匹配模型输入层的大小以进行特征提取。图像数组转换为 float32 类型并reshape,然后做归一化。
# opencv读取图像 并resize为(224,224)
images = [cv.resize(cv.imread(str(file)), (224, 224)) for file in files]
paths = [file for file in files]
# 图像数组转换为float32类型并reshape 然后做归一化
images = np.array(np.float32(images).reshape(len(images), -1) / 255)
加载预训练模型 MobileNetV2 来实现图像分类
# 加载预先训练的模型MobileNetV2来实现图像分类
model = tf.keras.applications.MobileNetV2(include_top=False,
weights="imagenet", input_shape=(224, 224, 3))
predictions = model.predict(images.reshape(-1, 224, 224, 3))
pred_images = predictions.reshape(images.shape[0], -1)
k-means聚类算法
k = 2 # 2个类别
# K-Means聚类
kmodel = KMeans(n_clusters=k, n_jobs=-1, random_state=888)
kmodel.fit(pred_images)
kpredictions = kmodel.predict(pred_images)
print(kpredictions) # 预测的类别
# 0:dog 1:cat
将分类后的图像保存到不同文件夹下
for i in ["cat", "dog"]:
os.mkdir(r"C:\Users\Administrator\DeepLearning\picture_" + str(i))
# 复制文件,保留元数据 shutil.copy2('来源文件', '目标地址')
for i in range(len(paths)):
if kpredictions[i] == 0:
shutil.copy2(paths[i], r"C:\Users\Administrator\DeepLearning\picture_dog")
else:
shutil.copy2(paths[i], r"C:\Users\Administrator\DeepLearning\picture_cat")
结果如下:
猫狗图像分类
推荐阅读:
https://keras-cn.readthedocs.io/en/latest/other/application/
https://www.freesion.com/article/6932673943/
https://mp.weixin.qq.com/s/64fgbm4QESz-irwY0uUYOA
到此这篇关于tensorflow+k-means聚类 简单实现猫狗图像分类的文章就介绍到这了,更多相关tensorflow实现猫狗图像分类内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!


 咨 询 客 服
咨 询 客 服