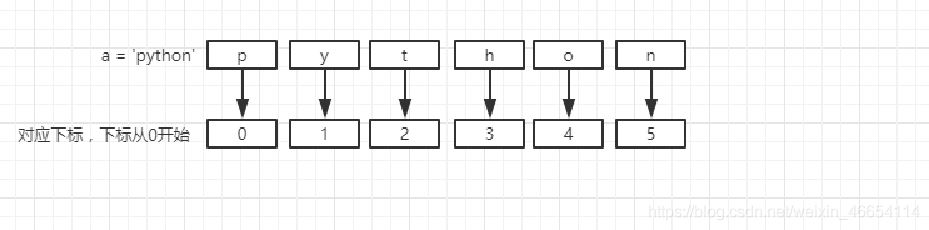
li=[] # 空列表
li=[1,2,3,4,'python',True]
print(type(li))
# #len函数可以获取到列表对象中的数据个数
print(len(li))
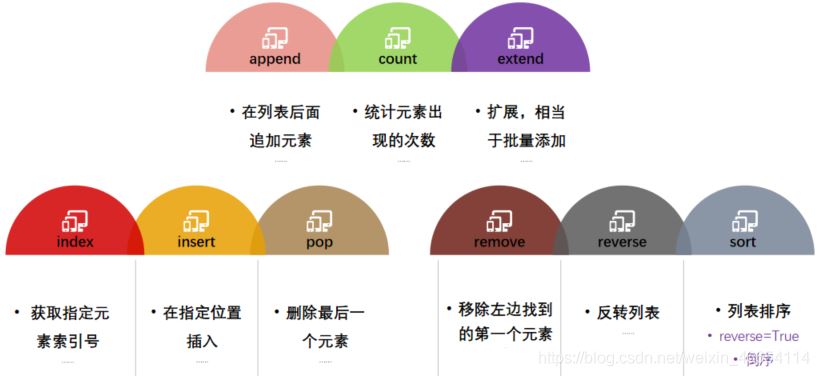
# append();在列表后面追加元素
# count(): 统计元素出现的次数
# extend(): 扩展,相当于批量添加
# index(): 获取指定元素索引号
# insert(): 在指定位置插入
# pop(): 删除后面一个元素
# remove():移除左边找到的第一个元素
# reverse(): 反转列表
# sort():列表排序 reverse=True为倒序
listA=['abcd',785,12.23,'qiuzhi',True]
# print('--------------增加-----------------------')
print('追加之前',listA)
listA.append(['fff','ddd']) #追加操作
listA.append(8888)
print('追加之后',listA)
listA.insert(1,'这是我刚插入的数据') #插入操作 需要执行一个位置插入
print(listA)
rsData=list(range(10)) #强制转换为list对象
print(type(rsData))
listA.extend(rsData) #拓展 等于批量添加
listA.extend([11,22,33,44])
print(listA)
# print('-----------------修改------------------------')
# print('修改之前',listA)
# listA[0]=333.6
# print('修改之后',listA)
listB=list(range(10,50))
print(type(listB))
print('------------删除list数据项------------------')
print(listB)
# del listB[0] #删除列表中第一个元素
# del listB[1:3] #批量删除多项数据 slice
# listB.remove(20) #移除指定的元素 参数是具体的数据值
listB.pop(1) #移除制定的项 参数是索引值
print(listB)
#beg -- 开始索引,默认为0。
#end -- 结束索引,默认为字符串的长度。
print(listB.index(19)) #返回的是一个索引下标
# 查找,跟元祖有点不一样,这是左开右闭
print(type(listA))
print(listA) #输出完整的列表
print(listA[0]) #输出第一个元素
print(listA[1:3]) #从第二个开始到第三个元素
print(listA[2:]) #从第三个元素开始到最后所有的元素
print(listA[::-1]) #负数从右像左开始输出
print(listA*3) #输出多次列表中的数据【复制】
a=[21,45,66,78]
b=[1,2]
def add100(x):
i= 0
for item in x:
x[i]=item+100
i+=1
pass
return x
pass
print(add100(b))
def add100(x):
x+=100
return x
list2=list(map(add100,a))
print(list2)
a=[21,45,66,78]
print(list(map(lambda x:x+100,a)))
def Old(x):
if x>50:
return x
pass
print(list(filter(Old,a)))
'''输出
class 'list'>
6
追加之前 ['abcd', 785, 12.23, 'qiuzhi', True]
追加之后 ['abcd', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888]
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888]
class 'list'>
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
class 'list'>
------------删除list数据项------------------
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49]
[10, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49]
8
class 'list'>
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
abcd
['这是我刚插入的数据', 785]
[785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
[44, 33, 22, 11, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, 8888, ['fff', 'ddd'], True, 'qiuzhi', 12.23, 785, '这是我刚插入的数据', 'abcd']
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44, 'abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44, 'abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
[101, 102]
[121, 145, 166, 178]
[121, 145, 166, 178]
[66, 78]
'''


 咨 询 客 服
咨 询 客 服