0 背景
由于工作需要,利用spark完成机器学习。因此需要对spark集群进行操作。所以利用pycharm和pyspark远程连接spark集群。这里记录下遇到的问题及方法。
主要是参照下面的文献完成相应的内容,但是具体问题要具体分析。
1 方法
1.1 软件配置
spark2.3.3, hadoop2.6, python3
1.2 spark配置
Spark集群的每个节点的Python版本必须保持一致。在每个节点的$SPARK_HOME/conf/spark-env.sh中添加一行:具体看你的安装目录。
export PYSPARK_PYTHON=/home/hadoop/anaconda2/bin/python3
此步骤就是将python添加到spark的配置中。
此时,在服务器命令行输入pyspark时,可以正常进入spark。
1.3本地配置
1.3.1 首先将spark2.3.3从服务器拷贝到本地。
注意: 由于我集群安装的是spark-2.3.3-bin-without-hadoop。但是拷贝到本地后,总是报错Java gateway process… 。同时我将hadoop2.6,的包也从服务器拷贝到本地加载到程序中,同样报错。
最后,直接从spark的官网中,下载了spark-2.3.3-bin-hadoop2.6,这回就可以了。
pyspark的版本与spark的版本最好对应。比如pyspark2.3.3,spark2.3.3
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"(无用)
os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"(有用)
# os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"(无用)
# os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"(无用)
1.3.2
C:\Windows\System32….\hosts(Windows机器)中加入Spark集群Master节点的IP与主机名的映射。需要管理员权限修改。

其中的spark_cluster就是对于Master的IP的映射名。(直接写IP一样可以,映射名是为了方便)
1.3.3
添加刚刚下载解压好的spark的python目录到pycharm的project structure
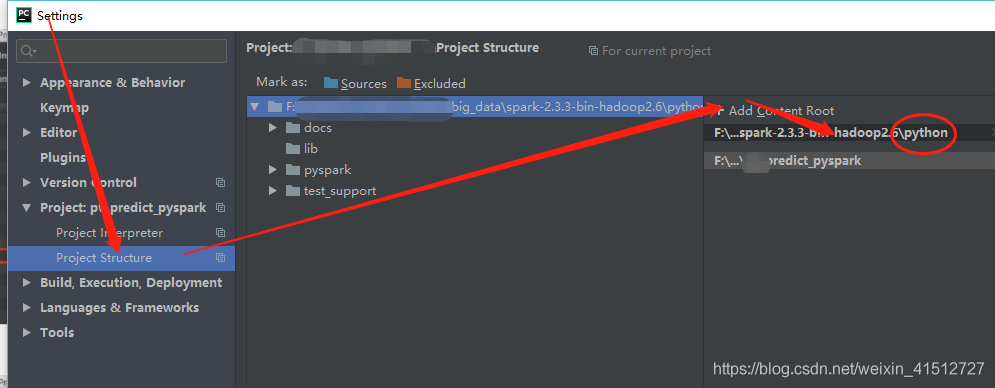
1.3.4
新建py文件,编辑Edit Configurations添加SPARK_HOME变量
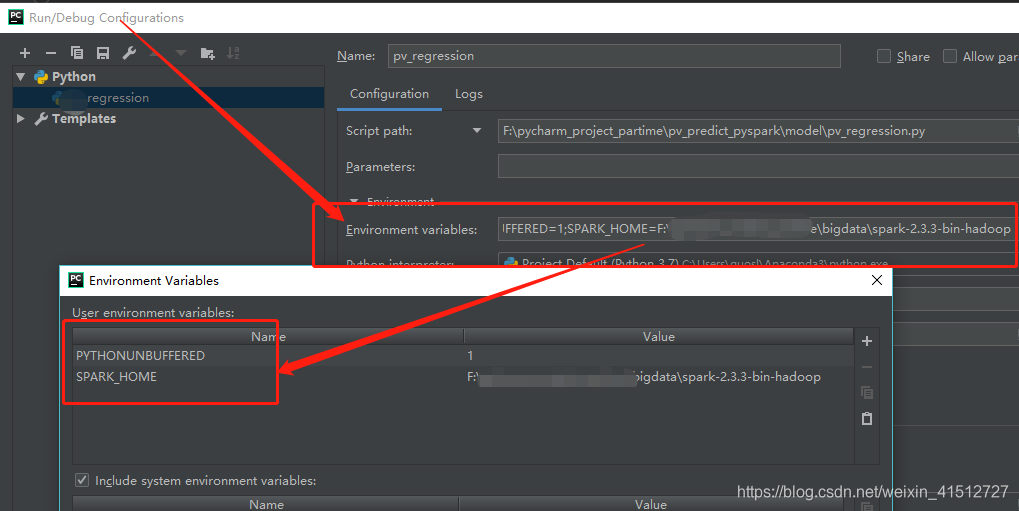
注意: 在实际中,这个不添加好像也可以。只需要在程序中加载了spark_home.比如os.envion(…spark…)
2 测试
import os
from pyspark import SparkContext
from pyspark import SparkConf
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"
os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"
# os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"
# os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"
print(0)
conf = SparkConf().setMaster("spark://spark_cluster:7077").setAppName("test")
sc = SparkContext(conf=conf)
print(1)
logData = sc.textFile("file:///opt/spark-2.3.3-bin-without-hadoop/README.md").cache()
print(2)
print("num of a",logData)
sc.stop()

3 参考
PyCharm+PySpark远程调试的环境配置的方法
Spark下:Java gateway process exited before sending the driver its port number等问题
估计每个人遇到的问题不一样,但是大同小异,具体问题具体分析。
到此这篇关于pycharm利用pyspark远程连接spark集群的实现的文章就介绍到这了,更多相关pyspark远程连接spark集群内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- pyspark 读取csv文件创建DataFrame的两种方法
- pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
- pyspark给dataframe增加新的一列的实现示例
- PyCharm搭建Spark开发环境实现第一个pyspark程序
- Linux下远程连接Jupyter+pyspark部署教程
- pycharm编写spark程序,导入pyspark包的3中实现方法
- 如何将PySpark导入Python的放实现(2种)
- pyspark对Mysql数据库进行读写的实现
- pyspark创建DataFrame的几种方法
- windowns使用PySpark环境配置和基本操作


 咨 询 客 服
咨 询 客 服