在利用DL解决图像问题时,影响训练效率最大的有时候是GPU,有时候也可能是CPU和你的磁盘。
很多设计不当的任务,在训练神经网络的时候,大部分时间都是在从磁盘中读取数据,而不是做 Backpropagation 。
这种症状的体现是使用 Nividia-smi 查看 GPU 使用率时,Memory-Usage 占用率很高,但是 GPU-Util 时常为 0% ,如下图所示:

如何解决这种问题呢?
在 Nvidia 提出的分布式框架 Apex 里面,我们在源码里面找到了一个简单的解决方案:
https://github.com/NVIDIA/apex/blob/f5cd5ae937f168c763985f627bbf850648ea5f3f/examples/imagenet/main_amp.py#L256
class data_prefetcher():
def __init__(self, loader):
self.loader = iter(loader)
self.stream = torch.cuda.Stream()
self.mean = torch.tensor([0.485 * 255, 0.456 * 255, 0.406 * 255]).cuda().view(1,3,1,1)
self.std = torch.tensor([0.229 * 255, 0.224 * 255, 0.225 * 255]).cuda().view(1,3,1,1)
# With Amp, it isn't necessary to manually convert data to half.
# if args.fp16:
# self.mean = self.mean.half()
# self.std = self.std.half()
self.preload()
def preload(self):
try:
self.next_input, self.next_target = next(self.loader)
except StopIteration:
self.next_input = None
self.next_target = None
return
with torch.cuda.stream(self.stream):
self.next_input = self.next_input.cuda(non_blocking=True)
self.next_target = self.next_target.cuda(non_blocking=True)
# With Amp, it isn't necessary to manually convert data to half.
# if args.fp16:
# self.next_input = self.next_input.half()
# else:
self.next_input = self.next_input.float()
self.next_input = self.next_input.sub_(self.mean).div_(self.std)
我们能看到 Nvidia 是在读取每次数据返回给网络的时候,预读取下一次迭代需要的数据,
那么对我们自己的训练代码只需要做下面的改造:
training_data_loader = DataLoader(
dataset=train_dataset,
num_workers=opts.threads,
batch_size=opts.batchSize,
pin_memory=True,
shuffle=True,
)
for iteration, batch in enumerate(training_data_loader, 1):
# 训练代码
#-------------升级后---------
data, label = prefetcher.next()
iteration = 0
while data is not None:
iteration += 1
# 训练代码
data, label = prefetcher.next()
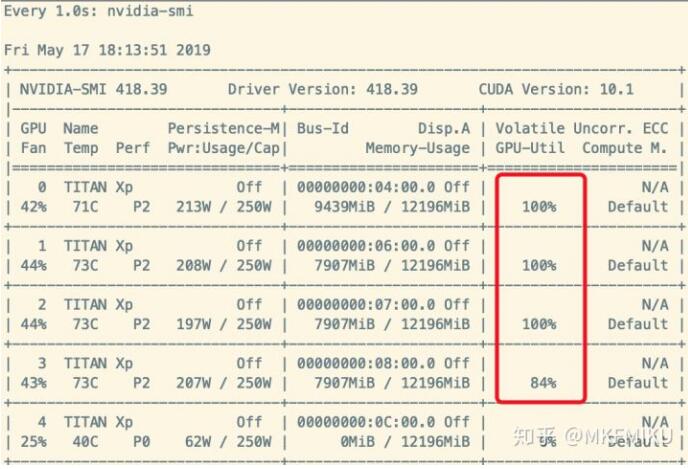
这样子我们的 Dataloader 就像打了鸡血一样提高了效率很多,如下图:
当然,最好的解决方案还是从硬件上,把读取速度慢的机械硬盘换成 NVME 固态吧~
补充:Pytorch设置多线程进行dataloader时影响GPU运行
使用PyTorch设置多线程(threads)进行数据读取时,其实是假的多线程,他是开了N个子进程(PID是连续的)进行模拟多线程工作。
以载入cocodataset为例
DataLoader
dataloader = torch.utils.data.DataLoader(COCODataset(config["train_path"],
(config["img_w"], config["img_h"]),
is_training=True),
batch_size=config["batch_size"],
shuffle=True, num_workers=32, pin_memory=True)
numworkers就是指定多少线程的参数,原为32。
检查GPU是否运行该程序
查看运行在gpu上的所有程序:
如果没有返回,则该程序并没有在GPU上运行
指定GPU运行
将num_workers改成0即可
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
您可能感兴趣的文章:- pytorch锁死在dataloader(训练时卡死)
- pytorch Dataset,DataLoader产生自定义的训练数据案例
- 解决Pytorch dataloader时报错每个tensor维度不一样的问题
- pytorch中DataLoader()过程中遇到的一些问题
- Pytorch dataloader在加载最后一个batch时卡死的解决
- pytorch DataLoader的num_workers参数与设置大小详解
- pytorch 实现多个Dataloader同时训练


 咨 询 客 服
咨 询 客 服