import os
import time
import json
import random
import csv
import re
import jieba
import requests
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 词云形状图片
WC_MASK_IMG = 'jdicon.jpg'
# 评论数据保存文件
COMMENT_FILE_PATH = 'jd_comment.txt'
# 词云字体
WC_FONT_PATH = '/Library/Fonts/Songti.ttc'
def spider_comment(page=0, key=0):
"""
爬取京东指定页的评价数据
:param page: 爬取第几,默认值为0
"""
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4646productId=' + key + '' \
'score=0sortType=5page=%spageSize=10isShadowSku=0fold=1' % page
kv = {'user-agent': 'Mozilla/5.0', 'Referer': 'https://item.jd.com/'+ key + '.html'}#原本key不输入值,默认为《三体》
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
except:
print('爬取失败')
# 截取json数据字符串
r_json_str = r.text[26:-2]
# 字符串转json对象
r_json_obj = json.loads(r_json_str)
# 获取评价列表数据
r_json_comments = r_json_obj['comments']
# 遍历评论对象列表
for r_json_comment in r_json_comments:
# 以追加模式换行写入每条评价
with open(COMMENT_FILE_PATH, 'a+') as file:
file.write(r_json_comment['content'] + '\n')
# 打印评论对象中的评论内容
print(r_json_comment['content'])
def batch_spider_comment():
"""
批量爬取某东评价
"""
# 写入数据前先清空之前的数据
if os.path.exists(COMMENT_FILE_PATH):
os.remove(COMMENT_FILE_PATH)
key = input("Please enter the address:")
key = re.sub("\D","",key)
#通过range来设定爬取的页面数
for i in range(10):
spider_comment(i,key)
# 模拟用户浏览,设置一个爬虫间隔,防止ip被封
time.sleep(random.random() * 5)
def cut_word():
"""
对数据分词
:return: 分词后的数据
"""
with open(COMMENT_FILE_PATH) as file:
comment_txt = file.read()
wordlist = jieba.cut(comment_txt, cut_all=False)#精确模式
wl = " ".join(wordlist)
print(wl)
return wl
def create_word_cloud():
"""44144127306
生成词云
:return:
"""
# 设置词云形状图片
wc_mask = np.array(Image.open(WC_MASK_IMG))
# 设置词云的一些配置,如:字体,背景色,词云形状,大小
wc = WordCloud(background_color="white", max_words=2000, mask=wc_mask, scale=4,
max_font_size=50, random_state=42, font_path=WC_FONT_PATH)
# 生成词云
wc.generate(cut_word())
# 在只设置mask的情况下,你将会得到一个拥有图片形状的词云
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.figure()
plt.show()
wc.to_file("jd_ciyun.jpg")
def txt_change_to_csv():
with open('jd_comment.csv', 'w+', encoding="utf8", newline='')as c:
writer_csv = csv.writer(c, dialect="excel")
with open("jd_comment.txt", 'r', encoding='utf8')as f:
# print(f.readlines())
for line in f.readlines():
# 去掉str左右端的空格并以空格分割成list
line_list = line.strip('\n').split(',')
print(line_list)
writer_csv.writerow(line_list)
if __name__ == '__main__':
# 爬取数据
batch_spider_comment()
#转换数据
txt_change_to_csv()
# 生成词云
create_word_cloud()
# -*-coding:utf-8-*-
def train():
from snownlp import sentiment
print("开始训练数据集...")
sentiment.train('negative.txt', 'positive.txt')#自己准备数据集
sentiment.save('sentiment.marshal')#保存训练模型
#python2保存的是sentiment.marshal;python3保存的是sentiment.marshal.3
"训练完成后,将训练完的模型,替换sentiment中的模型"
def main():
train() # 训练正负向商品评论数据集
print("数据集训练完成!")
if __name__ == '__main__':
main()
from snownlp import sentiment
import pandas as pd
import snownlp
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#from word_cloud import word_cloud_creation, word_cloud_implementation, word_cloud_settings
def read_csv():
'''读取商品评论数据文件'''
comment_data = pd.read_csv('jd_comment.csv', encoding='utf-8',
sep='\n', index_col=None)
#返回评论作为参数
return comment_data
def clean_data(data):
'''数据清洗'''
df = data.dropna() # 消除缺失数据 NaN为缺失数据
df = pd.DataFrame(df.iloc[:, 0].unique()) # 数据去重
return df
# print('数据清洗后:', len(df))
def clean_repeat_word(raw_str, reverse=False):
'''去除评论中的重复使用的词汇'''
if reverse:
raw_str = raw_str[::-1]
res_str = ''
for i in raw_str:
if i not in res_str:
res_str += i
if reverse:
res_str = res_str[::-1]
return res_str
def processed_data(filename):
'''清洗完毕的数据,并保存'''
df = clean_data(read_csv())#数据清洗
ser1 = df.iloc[:, 0].apply(clean_repeat_word)#去除重复词汇
df2 = pd.DataFrame(ser1.apply(clean_repeat_word, reverse=True))
df2.to_csv(f'{filename}.csv', encoding='utf-8', index_label=None, index=None)
def train():
'''训练正向和负向情感数据集,并保存训练模型'''
sentiment.train('negative.txt', 'positive.txt')
sentiment.save('seg.marshal')#python2保存的是sentiment.marshal;python3保存的是sentiment.marshal.3
sentiment_list = []
res_list = []
def test(filename, to_filename):
'''商品评论-情感分析-测试'''
with open(f'{filename}.csv', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
s = snownlp.SnowNLP(line)
#调用snownlp中情感评分s.sentiments
if s.sentiments > 0.6:
res = '喜欢'
res_list.append(1)
elif s.sentiments 0.4:
res = '不喜欢'
res_list.append(-1)
else:
res = '一般'
res_list.append(0)
sent_dict = {
'情感分析结果': s.sentiments,
'评价倾向': res,
'商品评论': line.replace('\n', '')
}
sentiment_list.append(sent_dict)
print(sent_dict)
df = pd.DataFrame(sentiment_list)
df.to_csv(f'{to_filename}.csv', index=None, encoding='utf-8',
index_label=None, mode='w')
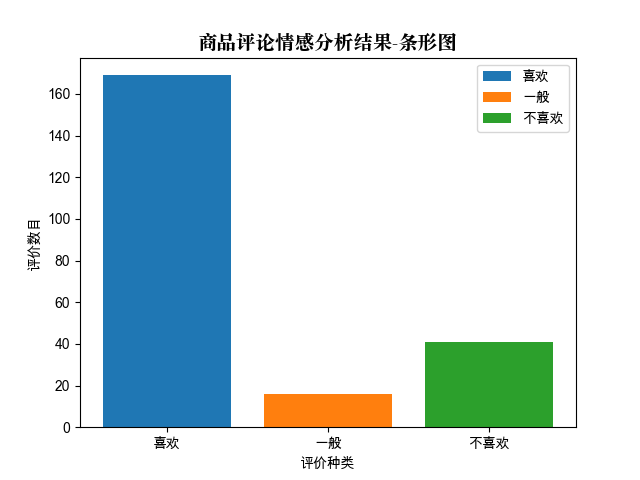
def data_virtualization():
'''分析结果可视化,以条形图为测试样例'''
font = FontProperties(fname='/System/Library/Fonts/Supplemental/Songti.ttc', size=14)
likes = len([i for i in res_list if i == 1])
common = len([i for i in res_list if i == 0])
unlikes = len([i for i in res_list if i == -1])
plt.bar([1], [likes], label='喜欢')#(坐标,评论长度,名称)
plt.bar([2], [common], label='一般')
plt.bar([3], [unlikes], label='不喜欢')
x=[1,2,3]
label=['喜欢','一般','不喜欢']
plt.xticks(x, label)
plt.legend()#插入图例
plt.xlabel('评价种类')
plt.ylabel('评价数目')
plt.title(u'商品评论情感分析结果-条形图', FontProperties=font)
plt.savefig('fig.png')
plt.show()
'''
def word_cloud_show():
#将商品评论转为高频词汇的词云
wl = word_cloud_creation('jd_comment.csv')
wc = word_cloud_settings()
word_cloud_implementation(wl, wc)
'''
def main():
processed_data('processed_comment_data')#数据清洗
#train() # 训练正负向商品评论数据集
test('jd_comment', 'result')
print('数据可视化中...')
data_virtualization() # 数据可视化
print('python程序运行结束。')
if __name__ == '__main__':
main()


 咨 询 客 服
咨 询 客 服