目录
- 一、技术路线
- 二、获取网页信息
- 三、网页爬取分析
- 四、网页详情页链接获取
- 五、依据图片链接保存图片
- 六、main()函数
- 七、完整代码
一、技术路线
requests:网页请求
BeautifulSoup:解析html网页
re:正则表达式,提取html网页信息
os:保存文件
import re
import requests
import os
from bs4 import BeautifulSoup
二、获取网页信息
常规操作,获取网页信息的固定格式,返回的字符串格式的网页内容,其中headers参数可模拟人为的操作,‘欺骗'网站不被发现
def getHtml(url): #固定格式,获取html内容
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
} #模拟用户操作
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('网络状态错误')
三、网页爬取分析
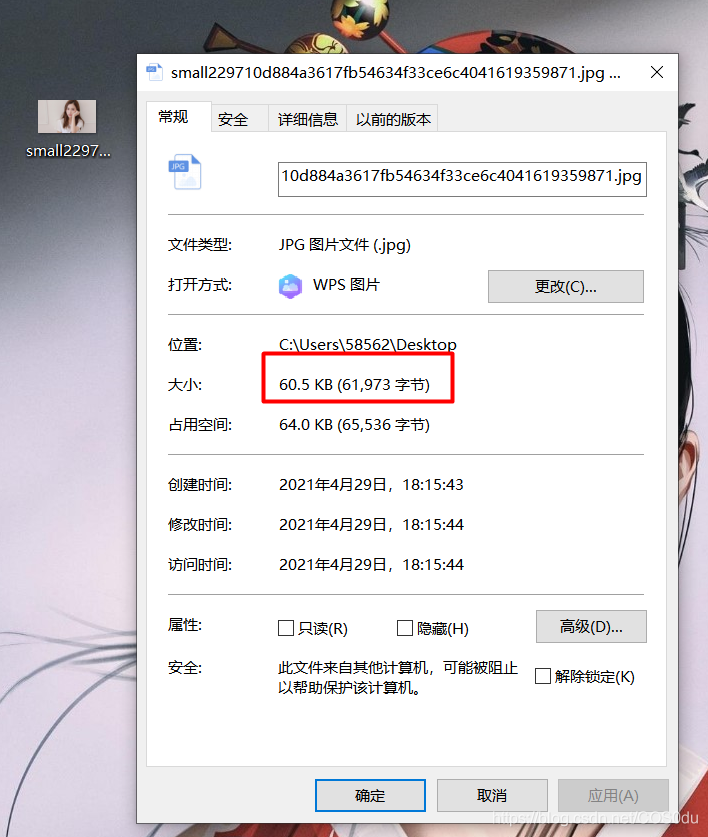
右键单击图片区域,选择 ‘审查元素' ,可以查看当前网页图片详情链接,我就满心欢喜的复制链接打开保存,看看效果,结果一张图片只有60几kb,这就是缩略图啊,不清晰,果断舍弃。。。

没有办法,只有点击找到详情页链接,再进行单独爬取。
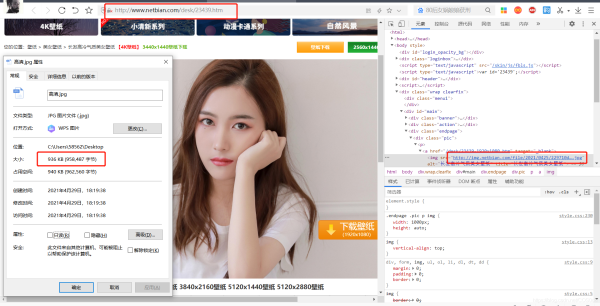
空白右键,‘查看页面源代码',把刚刚复制的缩略图链接复制查找快速定位,分析所有图片详情页链接存在div标签,并且class=‘list' 唯一,因此可以使用BeautifulSoup提取此标签。并且发现图片详情页链接在herf=后面(同时我们注意到有部分无效链接也在div标签中,观察它们异同,发现无效链接存在'https'字样,因此可在代码中依据此排出无效链接,对应第4条中的函数代码),只需提取出来再在前面加上网页首页链接即可打开,并且右键图片,‘审查元素',复制链接下载的图片接近1M,表示是高清图片了,到这一步我们只需调用下载保存函数即可保存图片

四、网页详情页链接获取
根据第3条分析的情况,首要目标是将每页的每个图片的详情页链接给爬取下来,为后续的高清图片爬取做准备,这里直接定义函数def getUrlList(url):
def getUrlList(url): # 获取图片链接
url_list = [] #存储每张图片的url,用于后续内容爬取
demo = getHtml(url)
soup = BeautifulSoup(demo,'html.parser')
sp = soup.find_all('div', class_="list") #class='list'在全文唯一,因此作为锚,获取唯一的div标签;注意,这里的网页源代码是class,但是python为了和class(类)做区分,在最后面添加了_
nls = re.findall(r'a href="(.*?)" rel="external nofollow" rel="external nofollow" ', str(sp)) #用正则表达式提取链接
for i in nls:
if 'https' in i: #因所有无效链接中均含有'https'字符串,因此直接剔除无效链接(对应第3条的分析)
continue
url_list.append('http://www.netbian.com' + i) #在获取的链接中添加前缀,形成完整的有效链接
return url_list
五、依据图片链接保存图片
同理,在第4条中获取了每个图片的详情页链接后,打开,右键图片'审查元素',复制链接即可快速定位,然后保存图片
def fillPic(url,page):
pic_url = getUrlList(url) #调用函数,获取当前页的所有图片详情页链接
path = './美女' # 保存路径
for p in range(len(pic_url)):
pic = getHtml(pic_url[p])
soup = BeautifulSoup(pic, 'html.parser')
psoup = soup.find('div', class_="pic") #class_="pic"作为锚,获取唯一div标签;注意,这里的网页源代码是class,但是python为了和class(类)做区分,在最后面添加了_
picUrl = re.findall(r'src="(.*?)"', str(psoup))[0] #利用正则表达式获取详情图片链接,因为这里返回的是列表形式,所以取第一个元素(只有一个元素,就不用遍历的方式了)
pic = requests.get(picUrl).content #打开图片链接,并以二进制形式返回(图片,声音,视频等要以二进制形式打开)
image_name ='美女' + '第{}页'.format(page) + str(p+1) + '.jpg' #给图片预定名字
image_path = path + '/' + image_name #定义图片保存的地址
with open(image_path, 'wb') as f: #保存图片
f.write(pic)
print(image_name, '下载完毕!!!')
六、main()函数
经过前面的主体框架搭建完毕之后,对整个程序做一个前置化,直接上代码
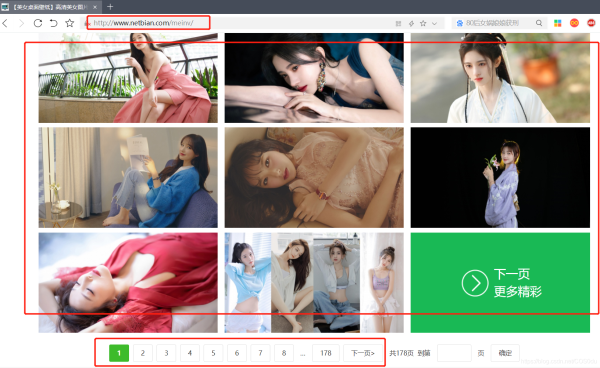
在这里第1页的链接是http://www.netbian.com/meinv/
第2页的链接是http://www.netbian.com/meinv/index_2.htm
并且后续页面是在第2页的基础上仅改变最后的数字,因此在写代码的时候要注意区分第1页和后续页面的链接,分别做处理;同时在main()函数还增加了自定义爬取页数的功能,详见代码
def main():
n = input('请输入要爬取的页数:')
url = 'http://www.netbian.com/meinv/' # 资源的首页,可根据自己的需求查看不同分类,自定义改变目录,爬取相应资源
if not os.path.exists('./美女'): # 如果不存在,创建文件目录
os.mkdir('./美女/')
page = 1
fillPic(url, page) # 爬取第一页,因为第1页和后续页的链接的区别,单独处理第一页的爬取
if int(n) >= 2: #爬取第2页之后的资源
ls = list(range(2, 1 + int(n)))
url = 'http://www.netbian.com/meinv/'
for i in ls: #用遍历的方法对输入的需求爬取的页面做分别爬取处理
page = str(i)
url_page = 'http://www.netbian.com/meinv/'
url_page += 'index_' + page + '.htm' #获取第2页后的每页的详情链接
fillPic(url, page) #调用fillPic()函数
七、完整代码
最后再调用main(),输入需要爬取的页数,即可开始爬取,完整代码如下
import re
import requests
import os
from bs4 import BeautifulSoup
def getHtml(url): #固定格式,获取html内容
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
} #模拟用户操作
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('网络状态错误')
def getUrlList(url): # 获取图片链接
url_list = [] #存储每张图片的url,用于后续内容爬取
demo = getHtml(url)
soup = BeautifulSoup(demo,'html.parser')
sp = soup.find_all('div', class_="list") #class='list'在全文唯一,因此作为锚,获取唯一的div标签;注意,这里的网页源代码是class,但是python为了和class(类)做区分,在最后面添加了_
nls = re.findall(r'a href="(.*?)" rel="external nofollow" rel="external nofollow" ', str(sp)) #用正则表达式提取链接
for i in nls:
if 'https' in i: #因所有无效链接中均含有'https'字符串,因此直接剔除无效链接(对应第3条的分析)
continue
url_list.append('http://www.netbian.com' + i) #在获取的链接中添加前缀,形成完整的有效链接
return url_list
def fillPic(url,page):
pic_url = getUrlList(url) #调用函数,获取当前页的所有图片详情页链接
path = './美女' # 保存路径
for p in range(len(pic_url)):
pic = getHtml(pic_url[p])
soup = BeautifulSoup(pic, 'html.parser')
psoup = soup.find('div', class_="pic") #class_="pic"作为锚,获取唯一div标签;注意,这里的网页源代码是class,但是python为了和class(类)做区分,在最后面添加了_
picUrl = re.findall(r'src="(.*?)"', str(psoup))[0] #利用正则表达式获取详情图片链接,因为这里返回的是列表形式,所以取第一个元素(只有一个元素,就不用遍历的方式了)
pic = requests.get(picUrl).content #打开图片链接,并以二进制形式返回(图片,声音,视频等要以二进制形式打开)
image_name ='美女' + '第{}页'.format(page) + str(p+1) + '.jpg' #给图片预定名字
image_path = path + '/' + image_name #定义图片保存的地址
with open(image_path, 'wb') as f: #保存图片
f.write(pic)
print(image_name, '下载完毕!!!')
def main():
n = input('请输入要爬取的页数:')
url = 'http://www.netbian.com/meinv/' # 资源的首页,可根据自己的需求查看不同分类,自定义改变目录,爬取相应资源
if not os.path.exists('./美女'): # 如果不存在,创建文件目录
os.mkdir('./美女/')
page = 1
fillPic(url, page) # 爬取第一页,因为第1页和后续页的链接的区别,单独处理第一页的爬取
if int(n) >= 2: #爬取第2页之后的资源
ls = list(range(2, 1 + int(n)))
url = 'http://www.netbian.com/meinv/'
for i in ls: #用遍历的方法对输入的需求爬取的页面做分别爬取处理
page = str(i)
url_page = 'http://www.netbian.com/meinv/'
url_page += 'index_' + page + '.htm' #获取第2页后的每页的详情链接
fillPic(url_page, page) #调用fillPic()函数
main()
到此这篇关于只用50行Python代码爬取网络美女高清图片的文章就介绍到这了,更多相关Python爬取图片内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python opencv通过按键采集图片源码
- 使用Python的Scrapy框架十分钟爬取美女图
- Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
- Python制作爬虫抓取美女图
- python制作花瓣网美女图片爬虫
- Python爬虫入门案例之回车桌面壁纸网美女图片采集


 咨 询 客 服
咨 询 客 服