一、分析数据源
这里的数据源是指html网页?还是Aajx异步。对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍。
提示:以下操作均不需要登录(当然登录也可以)
咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据。
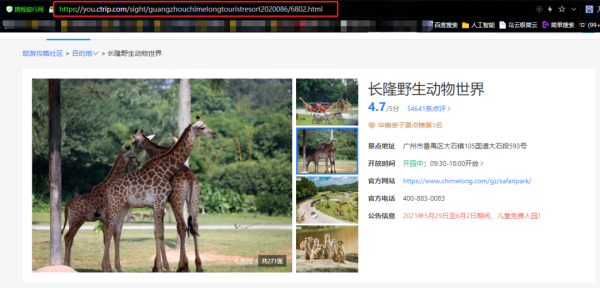
页面下方则是评论数据
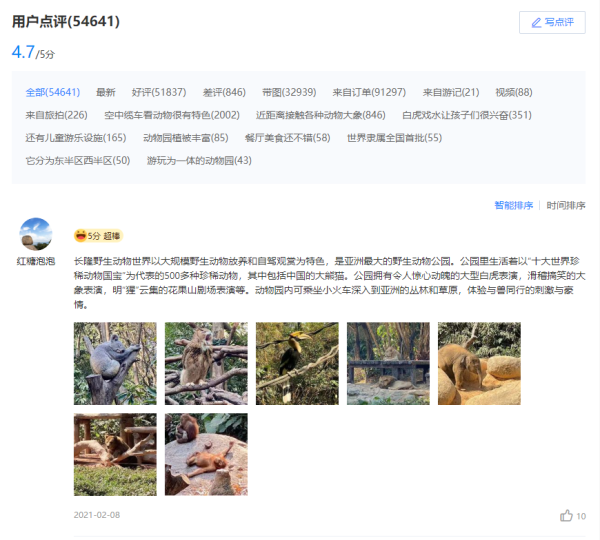
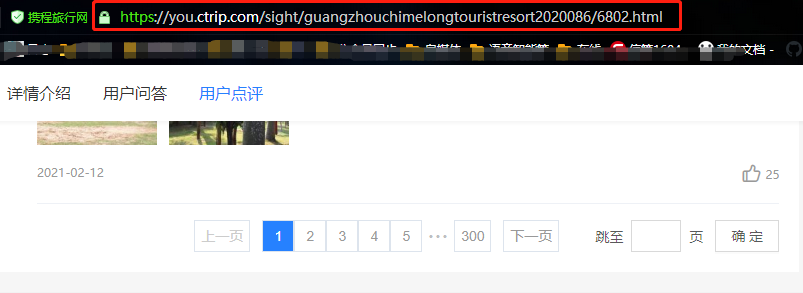
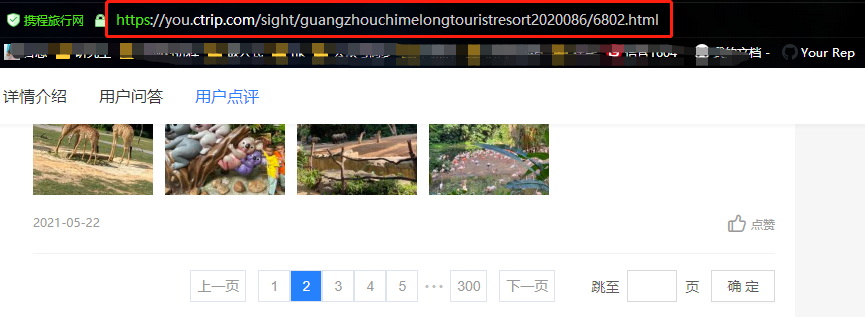
从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求。因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查看数据包。
二、分析数据包
在network中找到下面这个数据包
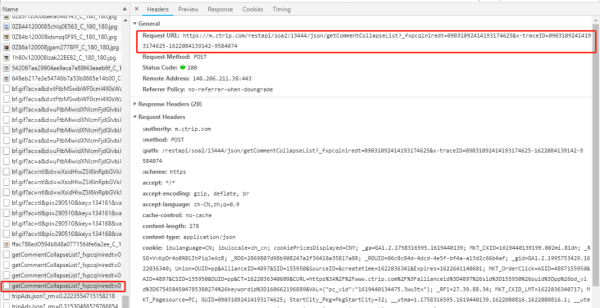
查看Preview里面的内容(请求返回内容)
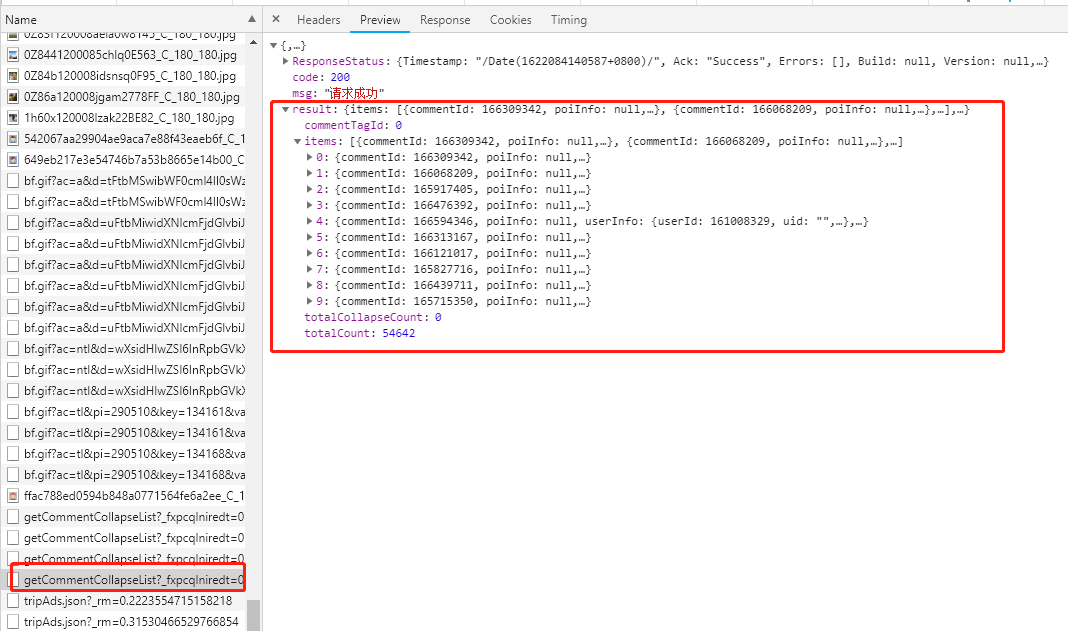
可以看到数据已经请求到了,下面看一下数据是否是正确的(和网页内容一致)。

ok,没问题之后,下面开始编写Python程序去请求数据。
1.请求地址

可以获取到请求链接和请求方式。
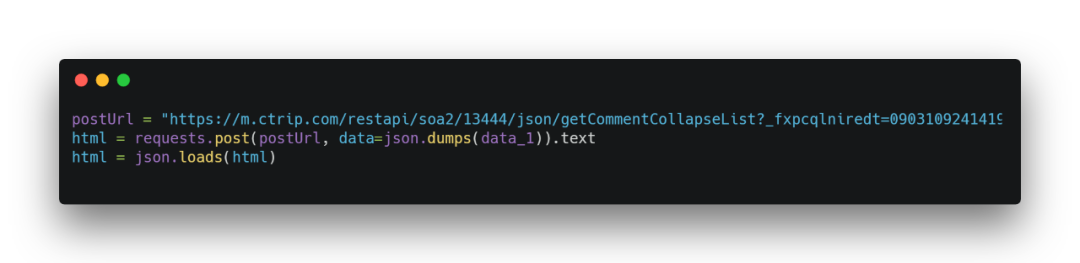
这里请求不用添加请求头header也是可以的。其中postUrl是请求链接,data_1是请求参数。
2.请求参数
在network里可以看到请求参数
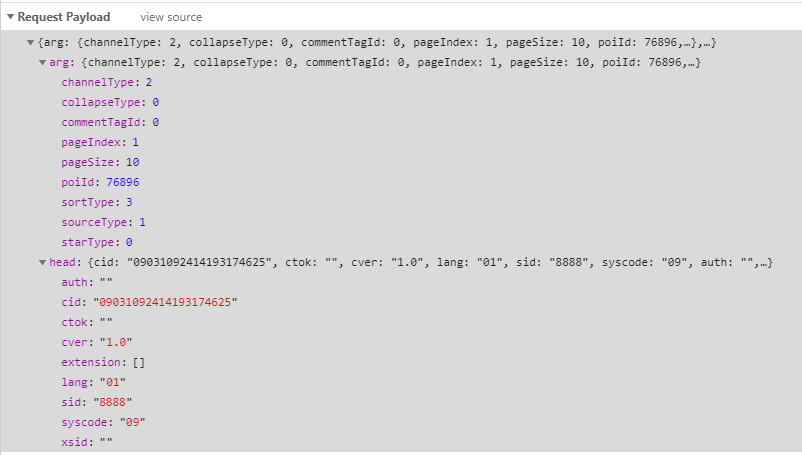
在程序中的构建如下:
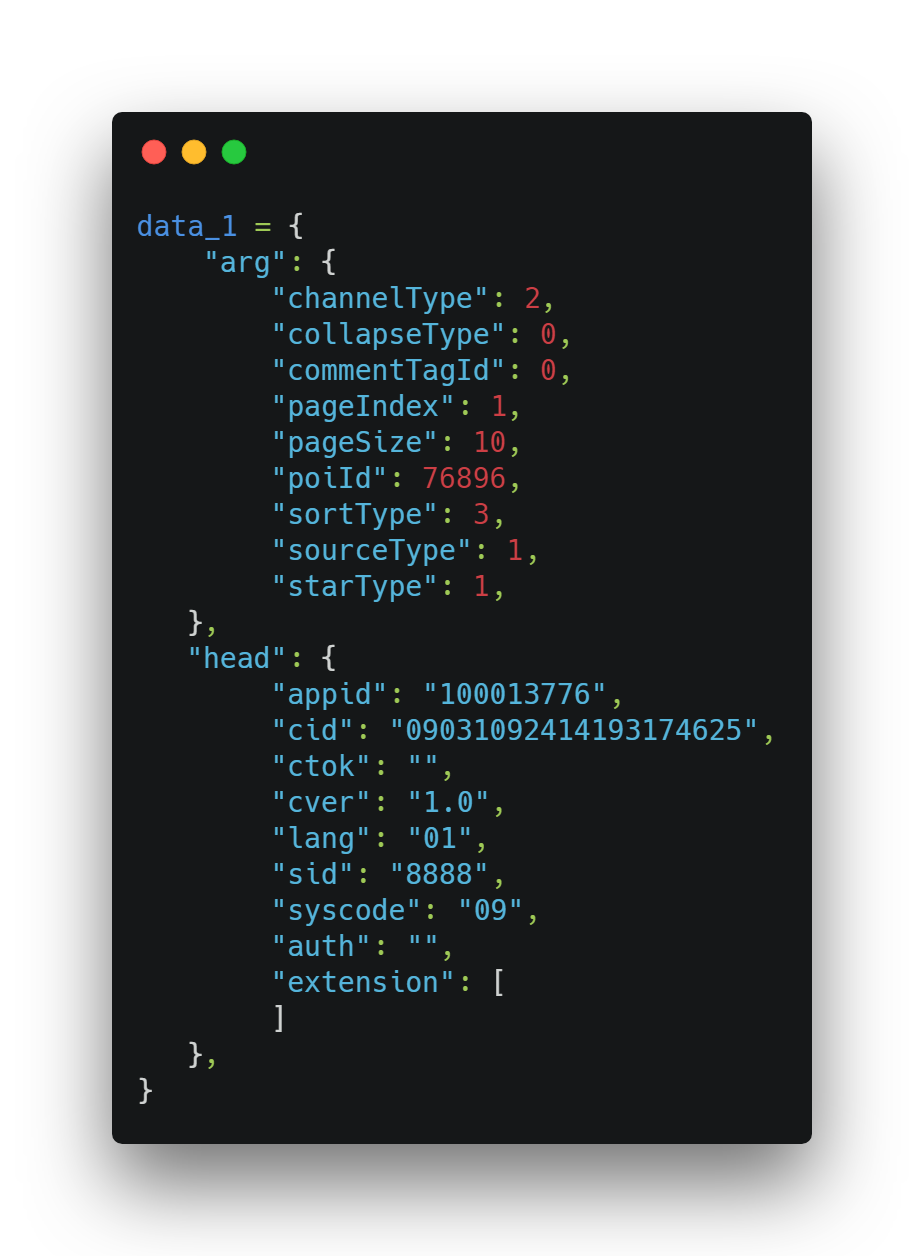
其中需要关注的是arg中的pageIndex(页数),pageSize(每页条数)。
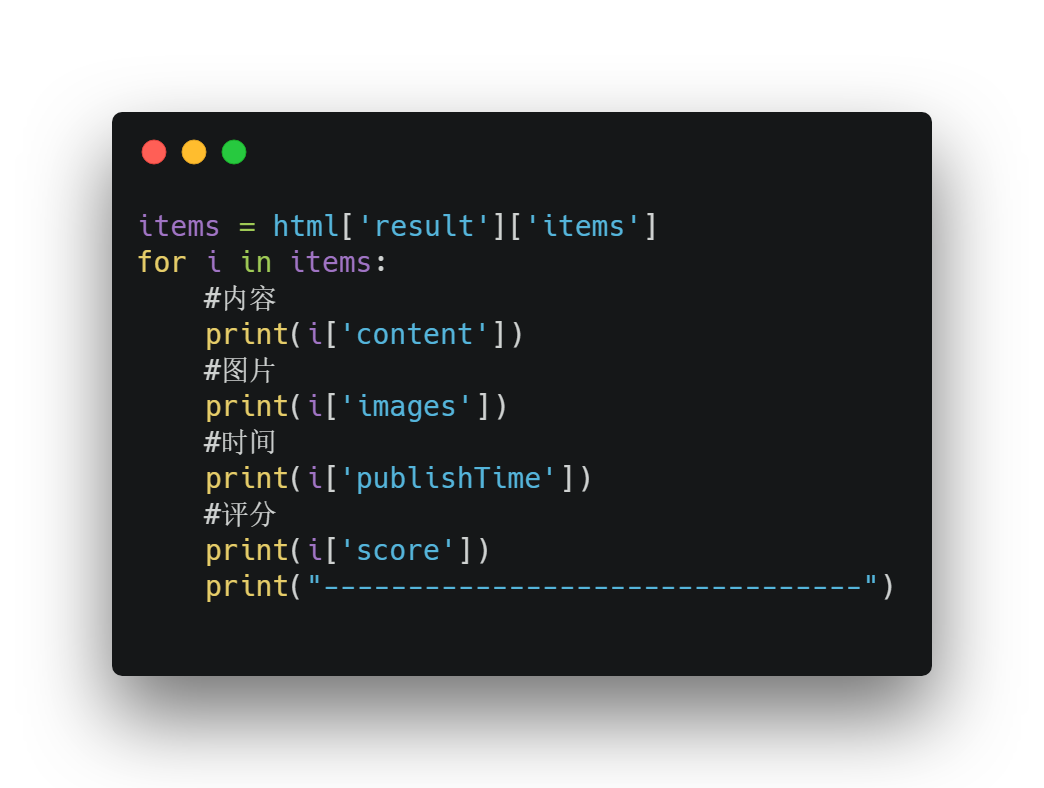
最终结果如下:

该景点的评论就可以成功爬取下来了。
三、采集全部评论
上面只是采集了第一页的评论数据,通过改变arg中的pageIndex(页数),就可以遍历爬取全部的评论。

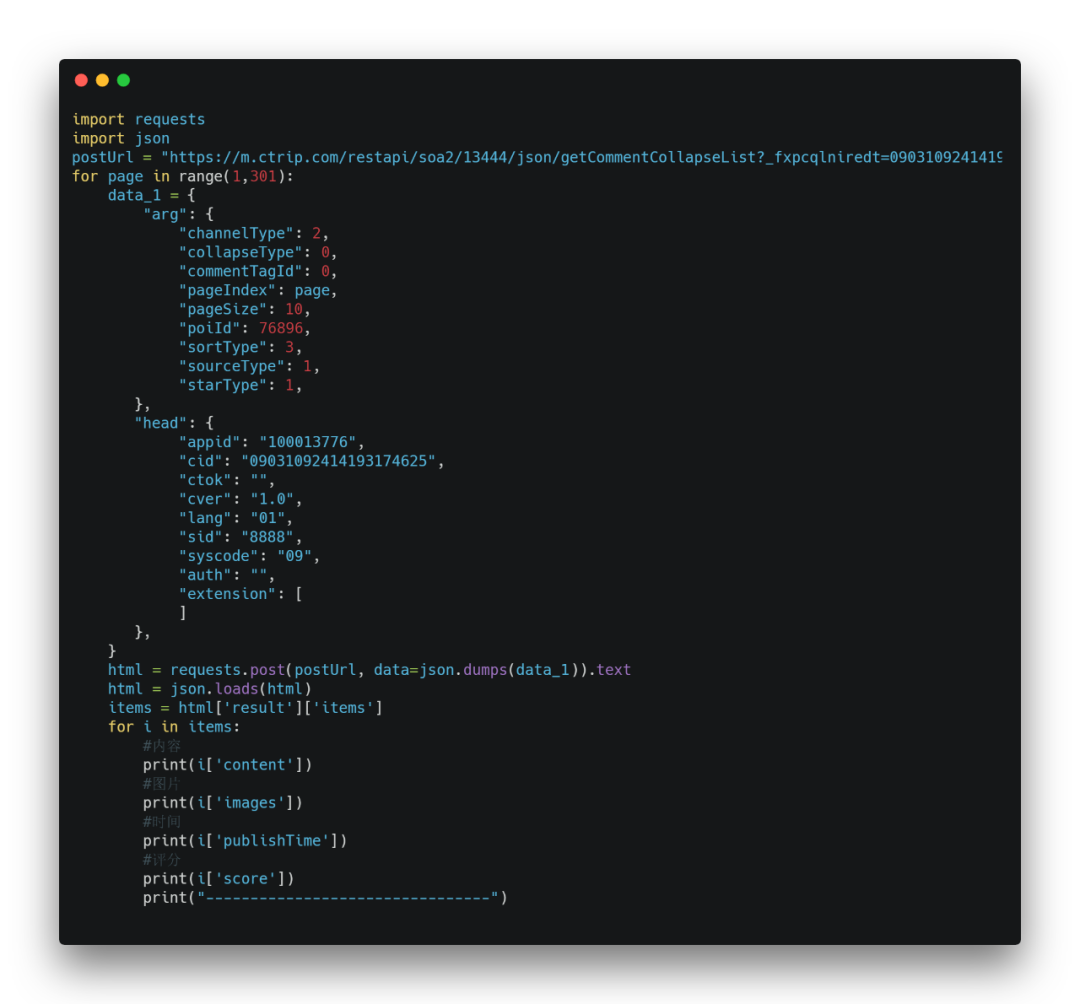
比如这个景点一共是300页。现在把循环给加上
最终的完整代码如下:
到此这篇关于Python爬虫实战之爬取携程评论的文章就介绍到这了,更多相关Python爬取携程评论内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python 爬取吉首大学网站成绩单
- python趣味挑战之爬取天气与微博热搜并自动发给微信好友
- python 爬取影视网站下载链接
- Python爬虫之爬取我爱我家二手房数据
- python 爬取京东指定商品评论并进行情感分析
- python结合多线程爬取英雄联盟皮肤(原理分析)
- python爬取豆瓣电影TOP250数据
- python爬取链家二手房的数据
- 教你怎么用python爬取爱奇艺热门电影
- Python爬虫之爬取最新更新的小说网站


 咨 询 客 服
咨 询 客 服