制作NBA数据爬虫
捋顺思路
我们在这里选择的是百度体育带来的数据,我们在百度当中直接搜索NBA跳转到网页,我们可以看到,百度已经为我们提供了相关的数据
我们点击进去后,可以发现这是一个非常简洁的网址
我们看一下这个地址栏,发现毫无规律https://tiyu.baidu.com/live/detail/576O5Zu955S35a2Q6IGM5Lia56%2Bu55CD6IGU6LWbI2Jhc2tldGJhbGwjMjAyMS0wNi0xMyPniLXlo6t2c%2BWspritq%2BiIuQ%3D%3D/from/baidu_aladdin

好吧,只能再找找了,我们点击整个标签发现,这是一个网址,那就容易多了。
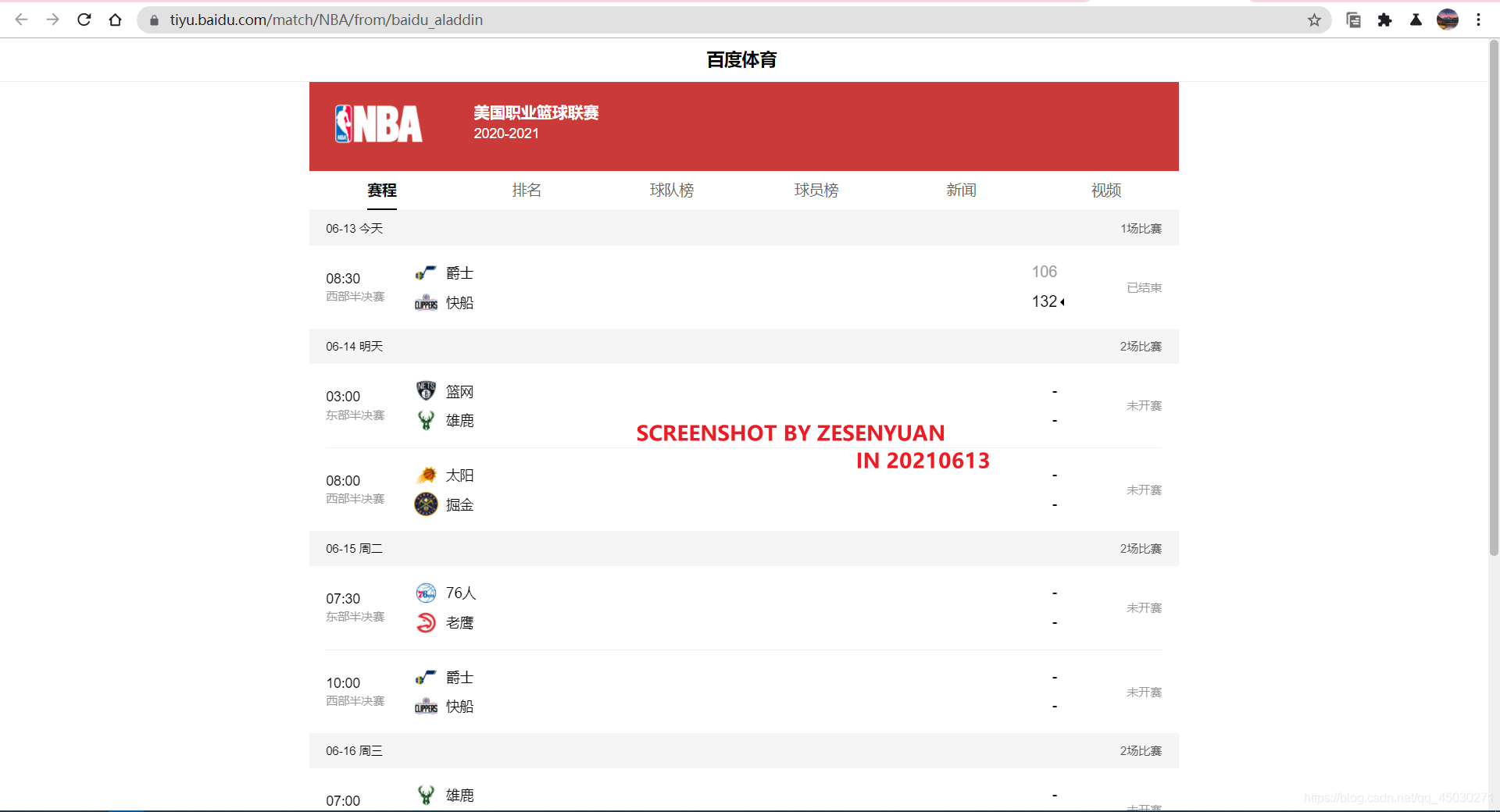
这里我们想要获取的无非就是具体的每一节数据和总分,然后如果用户还有其他需求的话我们就直接将其推送到百度网址上面来
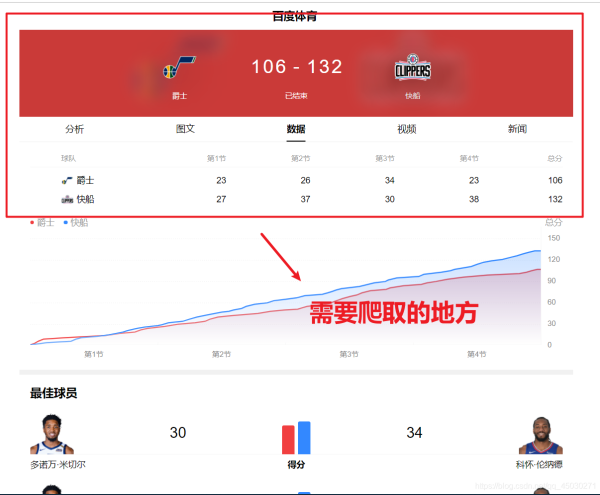
爬取的思路大概就是这样,首先先访问主页面,然后在访问旗下今天的比赛,最后将比赛结果返回
编写代码
首先我们使用REQUESTS来访问网址
我们可以看到,百度没有做任何限制,直接访问也可以获得内容
接下来我们使用解析库进行解析
首先我们先将程序定位到Main标签
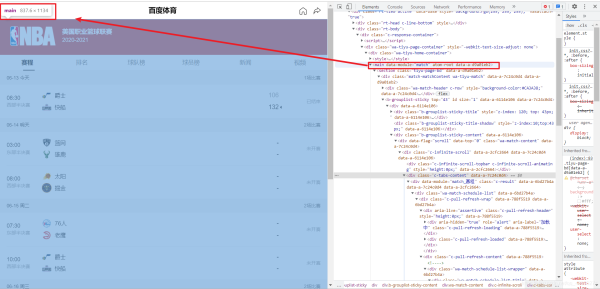
代码则是这样的,运行代码我们会发现,整个代码缩进了不少
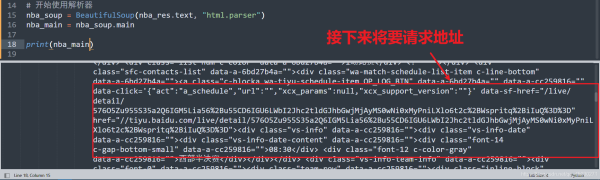
获取主要的页面,我们使用FIND函数进行进一步操作
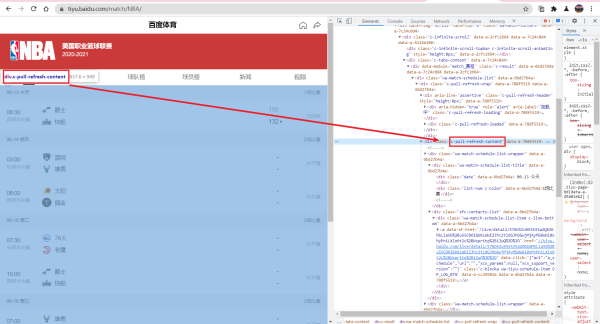
我们成功定位到了这个主页面,接下来就是我们开始爬取最近几次的比赛信息和详细页面了
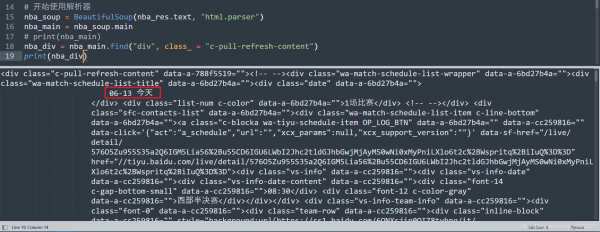
更改代码,我们直接获取所有的比赛信息

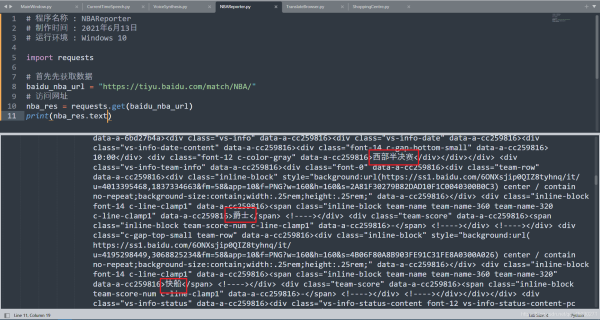
在测试网站的时候,我发现百度竟然使用了AJAX技术,就是说你一次性获得的网站源代码可能只有五条,然后要进行再一次加载才能获取接下来的数据。但是这也对我们程序来说挺好的,我们本来也不需要那么多数据。
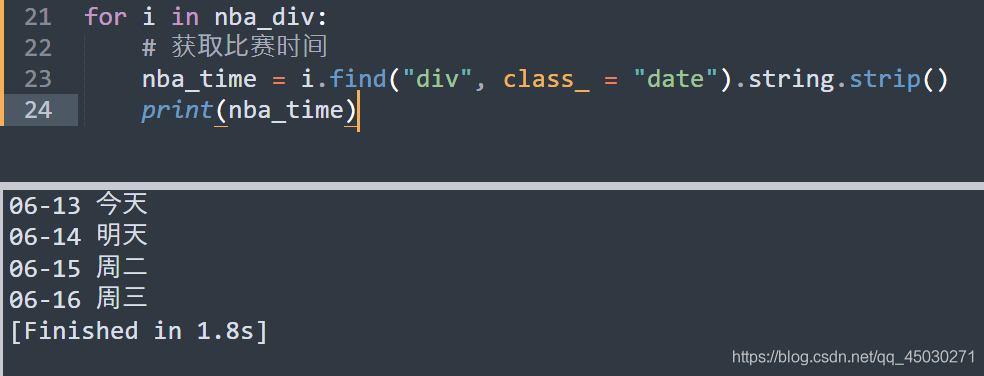
我们在这里查找了每一个的日期,查找对象为 date,接下来我们把其转换成字符串,因为百度上面这个日期有缩进,所以我们在后面添加 STRIP() 取消字符串前面的空格。按照这样的方式获取比赛地址

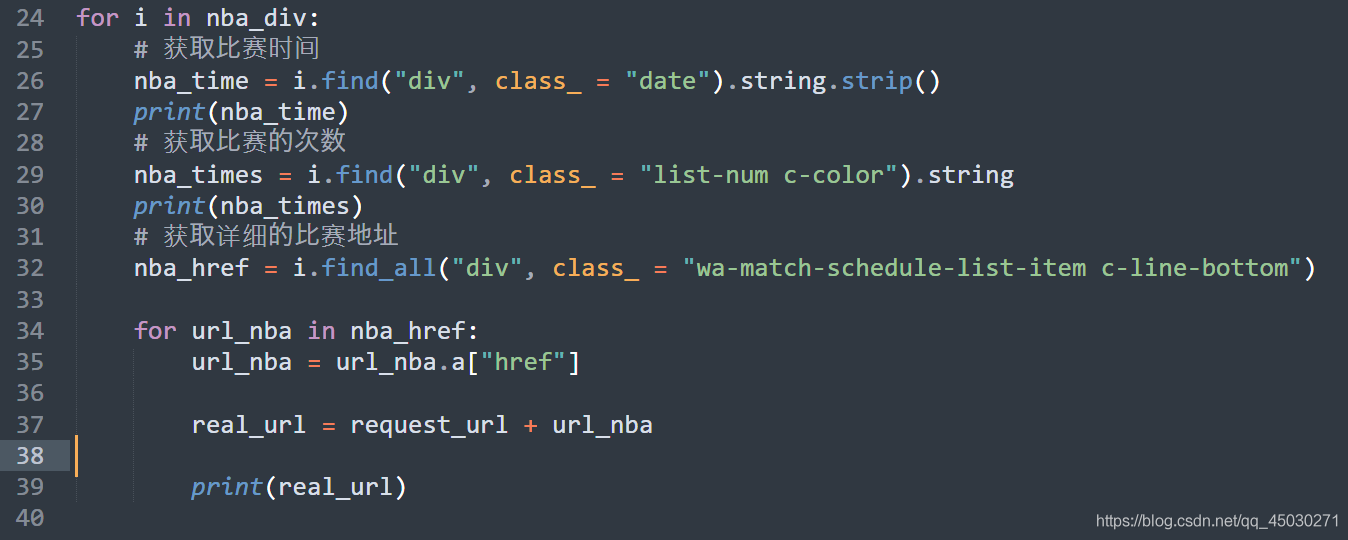
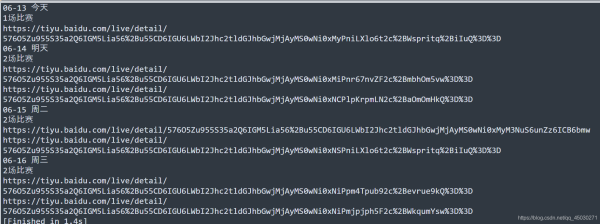
在这里,我们使用拼接字符串的方法,完成了对最后地址的解析
# 程序名称 : NBAReporter
# 制作时间 : 2021年6月13日
# 运行环境 : Windows 10
import requests
from bs4 import BeautifulSoup
# 基础数据定义
baidu_nba_url = "https://tiyu.baidu.com/match/NBA/"
request_url = "https:"
nba_dict = {}
# 访问网址
nba_res = requests.get(baidu_nba_url)
# print(nba_res.text)
# 开始使用解析器
nba_soup = BeautifulSoup(nba_res.text, "html.parser")
nba_main = nba_soup.main
# print(nba_main)
nba_div = nba_main.find_all("div", class_ = "wa-match-schedule-list-wrapper")
for i in nba_div:
# 获取比赛时间
nba_time = i.find("div", class_ = "date").string.strip()
print(nba_time)
# 获取比赛的次数
nba_times = i.find("div", class_ = "list-num c-color").string
print(nba_times)
# 获取详细的比赛地址
nba_href = i.find_all("div", class_ = "wa-match-schedule-list-item c-line-bottom")
for url_nba in nba_href:
url_nba = url_nba.a
url_href = url_nba["href"]
real_url = request_url + url_href
print(real_url)
接下来我们要开始剩余部分的解析,我们可以看到我们还有一部分的详细信息没有爬取,所以我们开始爬取详细信息
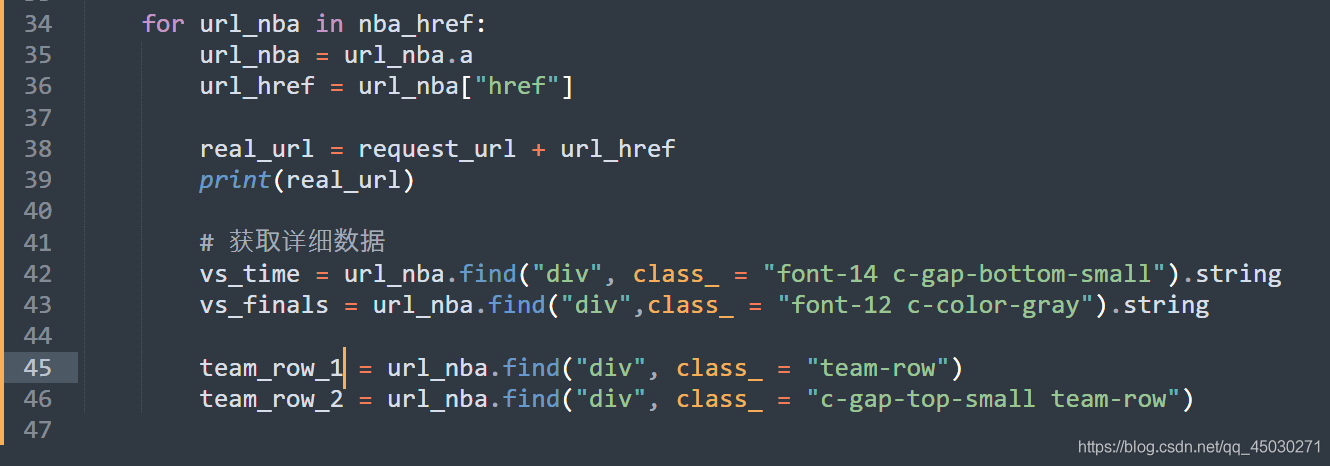
按照逻辑继续编写代码
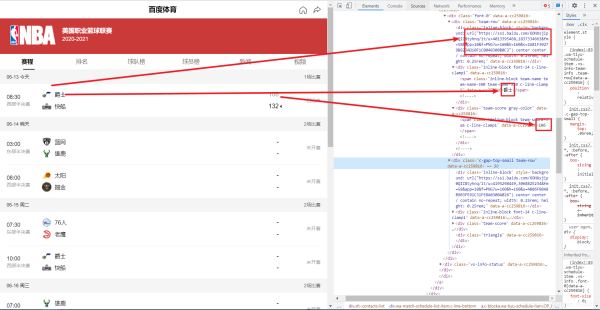
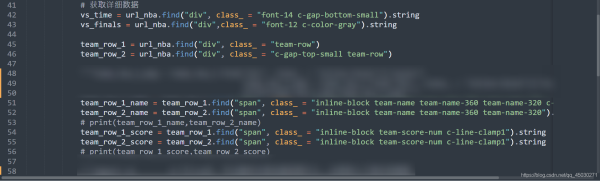
然后我们获取一下这里面的值
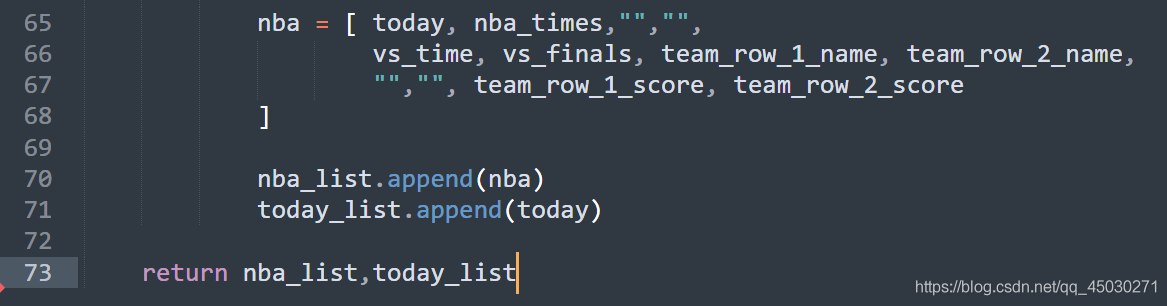
获取比赛的相关分数后,我们创建两个列表,一个列表定义我们等一下需要用到NBA的样式,另一个列表则存储今天的日期,最后返回
我们已经在这里吧这个方法封装了,所以我们创建一个新的文件,直接导入即可
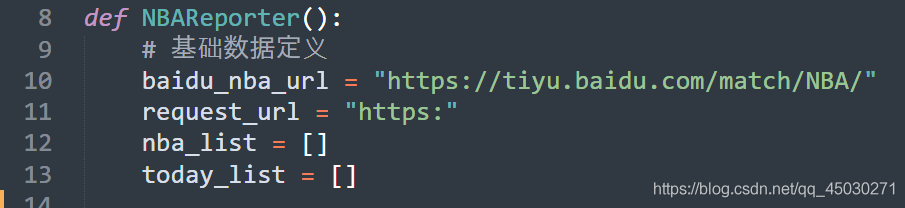
NBAReporter.py
# 程序名称 : NBAReporter
# 制作时间 : 2021年6月13日
# 运行环境 : Windows 10
import requests
from bs4 import BeautifulSoup
def NBAReporter():
# 基础数据定义
baidu_nba_url = "https://tiyu.baidu.com/match/NBA/"
request_url = "https:"
nba_list = []
today_list = []
# 访问网址
nba_res = requests.get(baidu_nba_url)
# print(nba_res.text)
# 开始使用解析器
nba_soup = BeautifulSoup(nba_res.text, "html.parser")
nba_main = nba_soup.main
# print(nba_main)
nba_div = nba_main.find_all("div", class_ = "wa-match-schedule-list-wrapper")
for i in nba_div:
# 获取比赛时间
today = i.find("div", class_ = "date").string.strip()
# 获取比赛的次数
nba_times = i.find("div", class_ = "list-num c-color").string
# 获取详细的比赛地址
nba_href = i.find_all("div", class_ = "wa-match-schedule-list-item c-line-bottom")
for url_nba in nba_href:
url_nba = url_nba.a
url_href = url_nba["href"]
real_url = request_url + url_href
# print(real_url)
# 获取详细数据
vs_time = url_nba.find("div", class_ = "font-14 c-gap-bottom-small").string
vs_finals = url_nba.find("div",class_ = "font-12 c-color-gray").string
team_row_1 = url_nba.find("div", class_ = "team-row")
team_row_2 = url_nba.find("div", class_ = "c-gap-top-small team-row")
"""team_row_1_png = team_row_1.find("div", class_ = "inline-block")["style"]
team_row_2_png = team_row_2.find("div", class_ = "inline-block")["style"]
print(team_row_1_png,team_row_2_png)"""
team_row_1_name = team_row_1.find("span", class_ = "inline-block team-name team-name-360 team-name-320 c-line-clamp1").string
team_row_2_name = team_row_2.find("span", class_ = "inline-block team-name team-name-360 team-name-320").string
# print(team_row_1_name,team_row_2_name)
team_row_1_score = team_row_1.find("span", class_ = "inline-block team-score-num c-line-clamp1").string
team_row_2_score = team_row_2.find("span", class_ = "inline-block team-score-num c-line-clamp1").string
# print(team_row_1_score,team_row_2_score)
"""import re # 导入re库,不过最好还是在最前面导入,这里是为了演示的需要
team_row_1_png_url = re.search(r'background:url(.*)', team_row_1_png)
team_row_1_png_url = team_row_1_png_url.group(1)
team_row_2_png_url = re.search(r'background:url(.*)', team_row_2_png)
team_row_2_png_url = team_row_2_png_url.group(1)"""
nba = [ today, nba_times,"","",
vs_time, vs_finals, team_row_1_name, team_row_2_name,
"","", team_row_1_score, team_row_2_score
]
nba_list.append(nba)
today_list.append(today)
return nba_list,today_list
这里我们要编写的是GUI界面的实现程序
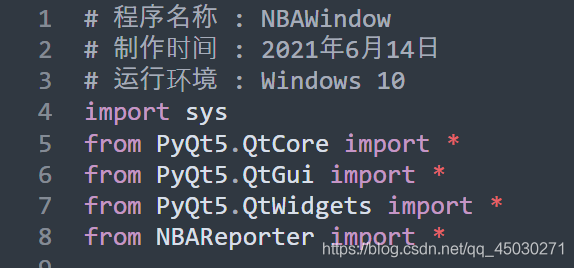
首先先导入我们运行所需要的库
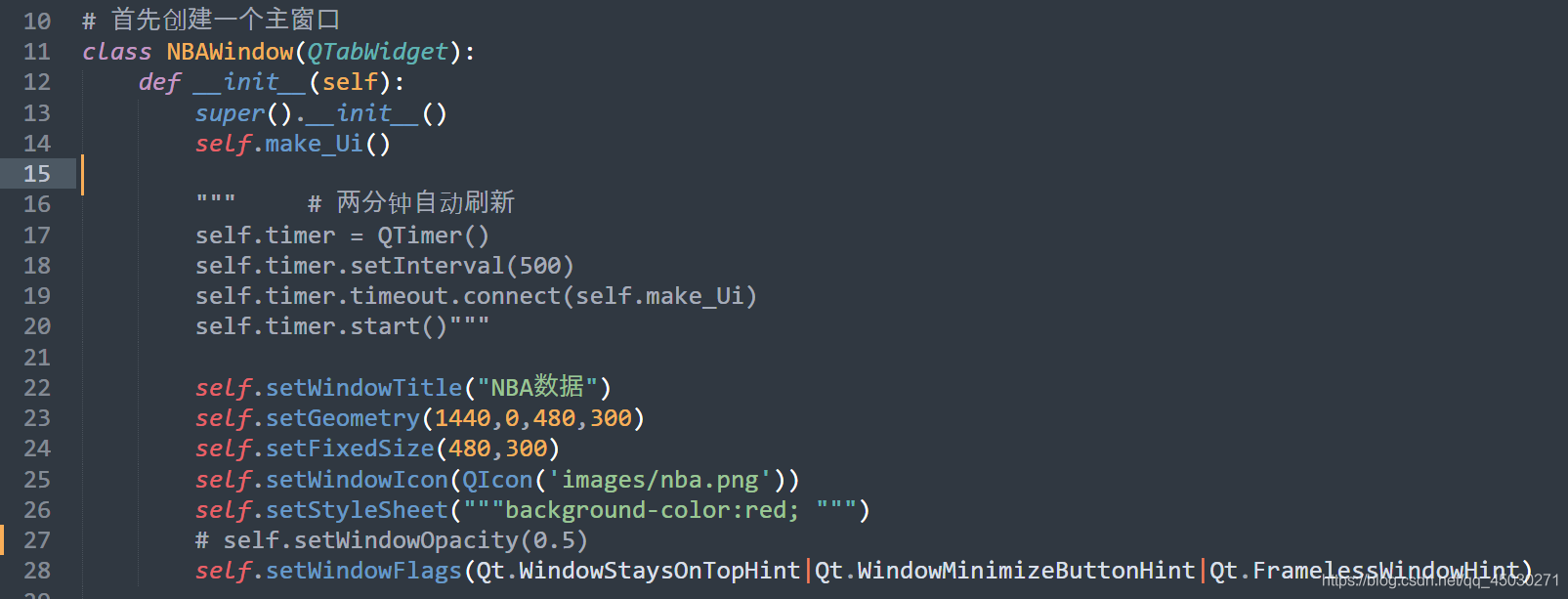
简单定义一下我们的代码,设置标题和其他的一些窗口属性# self.setWindowOpacity(0.5)这里是设置窗口透明程度的一行代码,但是经过我的测验之后,发现这样子真的对于用户体验一点也不好,所以在这里我把它注释掉了
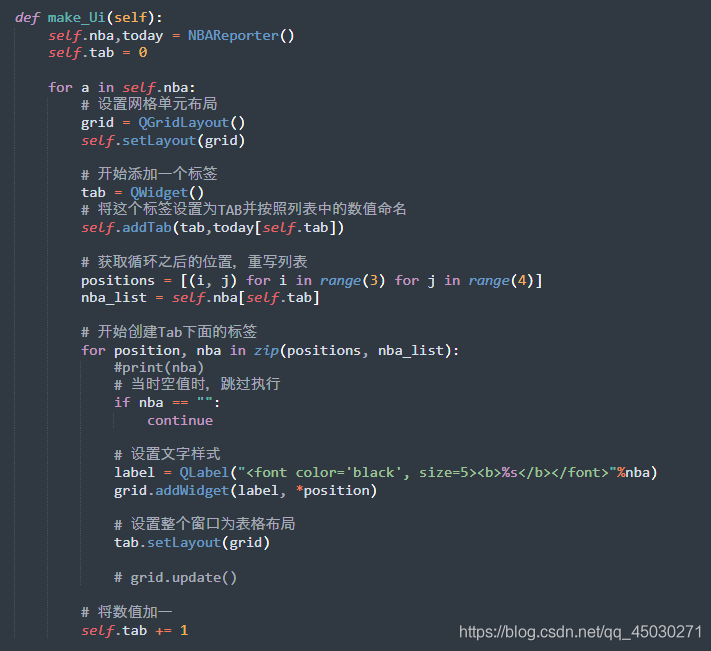
程序主逻辑如上图所示,我们创建了一个单元布局,然后又创建了和比赛一样的若干个标签,最后将函数返回的列表以标签的形式放在主窗口上面
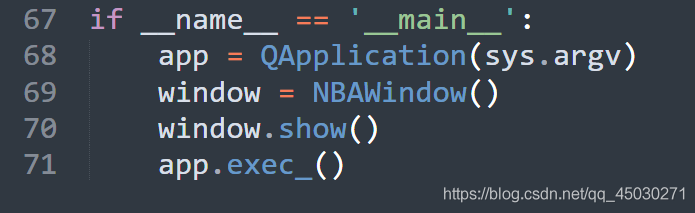
最后创建事件,运行程序,这样子整个程序就完成了
NBAWindow.py
# 程序名称 : NBAWindow
# 制作时间 : 2021年6月14日
# 运行环境 : Windows 10
import sys
from PyQt5.QtCore import *
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from NBAReporter import *
# 首先创建一个主窗口
class NBAWindow(QTabWidget):
def __init__(self):
super().__init__()
self.make_Ui()
""" # 两分钟自动刷新
self.timer = QTimer()
self.timer.setInterval(500)
self.timer.timeout.connect(self.make_Ui)
self.timer.start()"""
self.setWindowTitle("NBA数据")
self.setGeometry(1440,0,480,300)
self.setFixedSize(480,300)
self.setWindowIcon(QIcon('images/nba.png'))
self.setStyleSheet("""background-color:red; """)
# self.setWindowOpacity(0.5)
self.setWindowFlags(Qt.WindowStaysOnTopHint|Qt.WindowMinimizeButtonHint|Qt.FramelessWindowHint)
def make_Ui(self):
self.nba,today = NBAReporter()
self.tab = 0
for a in self.nba:
# 设置网格单元布局
grid = QGridLayout()
self.setLayout(grid)
# 开始添加一个标签
tab = QWidget()
# 将这个标签设置为TAB并按照列表中的数值命名
self.addTab(tab,today[self.tab])
# 获取循环之后的位置,重写列表
positions = [(i, j) for i in range(3) for j in range(4)]
nba_list = self.nba[self.tab]
# 开始创建Tab下面的标签
for position, nba in zip(positions, nba_list):
#print(nba)
# 当时空值时,跳过执行
if nba == "":
continue
# 设置文字样式
label = QLabel("font color='black', size=5>b>%s/b>/font>"%nba)
grid.addWidget(label, *position)
# 设置整个窗口为表格布局
tab.setLayout(grid)
# grid.update()
# 将数值加一
self.tab += 1
if __name__ == '__main__':
app = QApplication(sys.argv)
window = NBAWindow()
window.show()
app.exec_()
NBAReporter.py
# 程序名称 : NBAReporter
# 制作时间 : 2021年6月13日
# 运行环境 : Windows 10
import requests
from bs4 import BeautifulSoup
def NBAReporter():
# 基础数据定义
baidu_nba_url = "https://tiyu.baidu.com/match/NBA/"
request_url = "https:"
nba_list = []
today_list = []
# 访问网址
nba_res = requests.get(baidu_nba_url)
# print(nba_res.text)
# 开始使用解析器
nba_soup = BeautifulSoup(nba_res.text, "html.parser")
nba_main = nba_soup.main
# print(nba_main)
nba_div = nba_main.find_all("div", class_ = "wa-match-schedule-list-wrapper")
for i in nba_div:
# 获取比赛时间
today = i.find("div", class_ = "date").string.strip()
# 获取比赛的次数
nba_times = i.find("div", class_ = "list-num c-color").string
# 获取详细的比赛地址
nba_href = i.find_all("div", class_ = "wa-match-schedule-list-item c-line-bottom")
for url_nba in nba_href:
url_nba = url_nba.a
url_href = url_nba["href"]
real_url = request_url + url_href
# print(real_url)
# 获取详细数据
vs_time = url_nba.find("div", class_ = "font-14 c-gap-bottom-small").string
vs_finals = url_nba.find("div",class_ = "font-12 c-color-gray").string
team_row_1 = url_nba.find("div", class_ = "team-row")
team_row_2 = url_nba.find("div", class_ = "c-gap-top-small team-row")
"""team_row_1_png = team_row_1.find("div", class_ = "inline-block")["style"]
team_row_2_png = team_row_2.find("div", class_ = "inline-block")["style"]
print(team_row_1_png,team_row_2_png)"""
team_row_1_name = team_row_1.find("span", class_ = "inline-block team-name team-name-360 team-name-320 c-line-clamp1").string
team_row_2_name = team_row_2.find("span", class_ = "inline-block team-name team-name-360 team-name-320").string
# print(team_row_1_name,team_row_2_name)
team_row_1_score = team_row_1.find("span", class_ = "inline-block team-score-num c-line-clamp1").string
team_row_2_score = team_row_2.find("span", class_ = "inline-block team-score-num c-line-clamp1").string
# print(team_row_1_score,team_row_2_score)
"""import re # 导入re库,不过最好还是在最前面导入,这里是为了演示的需要
team_row_1_png_url = re.search(r'background:url(.*)', team_row_1_png)
team_row_1_png_url = team_row_1_png_url.group(1)
team_row_2_png_url = re.search(r'background:url(.*)', team_row_2_png)
team_row_2_png_url = team_row_2_png_url.group(1)"""
nba = [ today, nba_times,"","",
vs_time, vs_finals, team_row_1_name, team_row_2_name,
"","", team_row_1_score, team_row_2_score
]
nba_list.append(nba)
today_list.append(today)
return nba_list,today_list
效果演示
到此这篇关于Python利用PyQt5制作一个获取网络实时NBA数据并播报的GUI程序的文章就介绍到这了,更多相关Python PyQt5数据播报程序内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python PyQt5运行程序把输出信息展示到GUI图形界面上
- python3+PyQt5图形项的自定义和交互 python3实现page Designer应用程序
- python3+PyQt5实现支持多线程的页面索引器应用程序
- python3+PyQt5重新实现QT事件处理程序
- 基于Python+Pyqt5开发一个应用程序


 咨 询 客 服
咨 询 客 服