| user_id | cate | shop_id | |
|---|---|---|---|
| count | 1.200000e+01 | 12.000000 | 12.000000 |
| mean | 6.468688e+05 | 10.666667 | 3594.000000 |
| std | 3.988181e+05 | 6.665151 | 373.271775 |
| min | 2.421410e+05 | 7.000000 | 3388.000000 |
| 25% | 3.901920e+05 | 7.000000 | 3388.000000 |
| 50% | 4.938730e+05 | 7.000000 | 3388.000000 |
| 75% | 9.824990e+05 | 10.250000 | 3586.250000 |
| max | 1.558165e+06 | 23.000000 | 4278.000000 |
res6
| user_id | cate | shop_id | |
|---|---|---|---|
| 0 | 390192 | 20 | 4178 |
| 1 | 390192 | 23 | 4179 |
| 2 | 390192 | 22 | 4278 |
| 3 | 1021819 | 7 | 3388 |
| 4 | 242141 | 7 | 3388 |
| 5 | 283284 | 7 | 3388 |
| 6 | 1558165 | 7 | 3388 |
| 7 | 533696 | 7 | 3388 |
| 8 | 982499 | 7 | 3388 |
| 9 | 493873 | 7 | 3388 |
| 10 | 493873 | 7 | 3388 |
| 11 | 982499 | 7 | 3389 |
res6['user_id'].value_counts()
390192 3 982499 2 493873 2 242141 1 1021819 1 533696 1 1558165 1 283284 1 Name: user_id, dtype: int64
res6.groupby(['user_id']).size().sort_values(ascending=False)
user_id 390192 3 982499 2 493873 2 1558165 1 1021819 1 533696 1 283284 1 242141 1 dtype: int64
res6.groupby(['user_id', 'cate']).size().sort_values(ascending=False)
user_id cate
982499 7 2
493873 7 2
1558165 7 1
1021819 7 1
533696 7 1
390192 23 1
22 1
20 1
283284 7 1
242141 7 1
dtype: int64
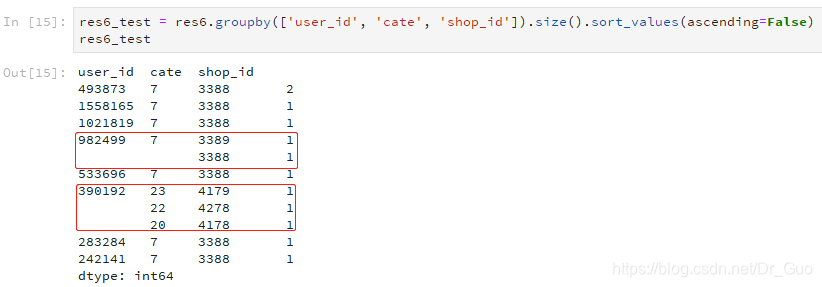
res6_test = res6.groupby(['user_id', 'cate', 'shop_id']).size().sort_values(ascending=False) res6_test
user_id cate shop_id
493873 7 3388 2
1558165 7 3388 1
1021819 7 3388 1
982499 7 3389 1
3388 1
533696 7 3388 1
390192 23 4179 1
22 4278 1
20 4178 1
283284 7 3388 1
242141 7 3388 1
dtype: int64
到此这篇关于python中pandas对多列进行分组统计的实现的文章就介绍到这了,更多相关pandas多列分组统计内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!

 咨 询 客 服
咨 询 客 服