scrapy 框架结构
思考
- scrapy 为什么是框架而不是库?
- scrapy是如何工作的?
项目结构
在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:
注意:创建项目时,会在当前目录下新建爬虫项目的目录。
这些文件分别是:
- scrapy.cfg:项目的配置文件
- quotes/:该项目的python模块。之后您将在此加入代码
- quotes/items.py:项目中的item文件
- quotes/middlewares.py:爬虫中间件、下载中间件(处理请求体与响应体)
- quotes/pipelines.py:项目中的pipelines文件
- quotes/settings.py:项目的设置文件
- quotes/spiders/:放置spider代码的目录
Scrapy原理图

各个组件的介绍
1.Engine。引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
2.ltem。项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该ltem对象。
3.Scheduler。调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎。
4.Downloader。下载器,下载网页内容,并将网页内容返回给蜘蛛。
5.Spiders。蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提结果和新的请求。
6.Item Pipeline。项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
7.Downloader Middlewares。下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
8.Spider Middlewares。蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
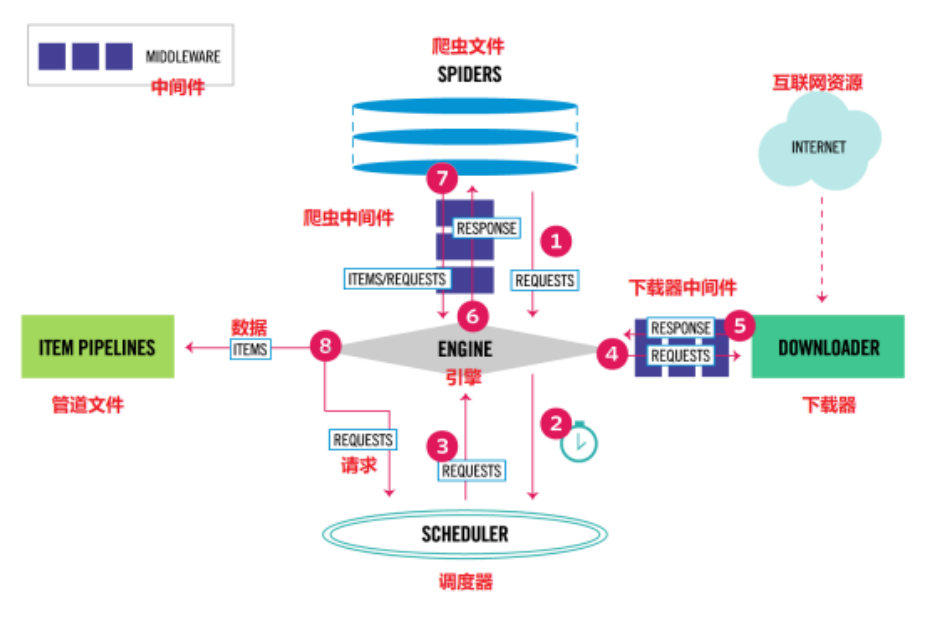
数据的流动
- Scrapy Engine(引擎):负责Spider、ltemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器):负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫)︰负责处理所有Responses,从中分析提取数据,获取ltem字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- ltem Pipeline(管道):负责处理Spider中获取到的ltem,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
到此这篇关于Python爬虫基础之简单说一下scrapy的框架结构的文章就介绍到这了,更多相关scrapy的框架结构内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python爬虫基础讲解之scrapy框架
- python爬虫scrapy框架的梨视频案例解析
- 简述python Scrapy框架
- Python Scrapy框架第一个入门程序示例


 咨 询 客 服
咨 询 客 服