一、前言
二、爬取观影数据
https://movie.douban.com/
在『豆瓣』平台爬取用户观影数据。
爬取用户列表
网页分析
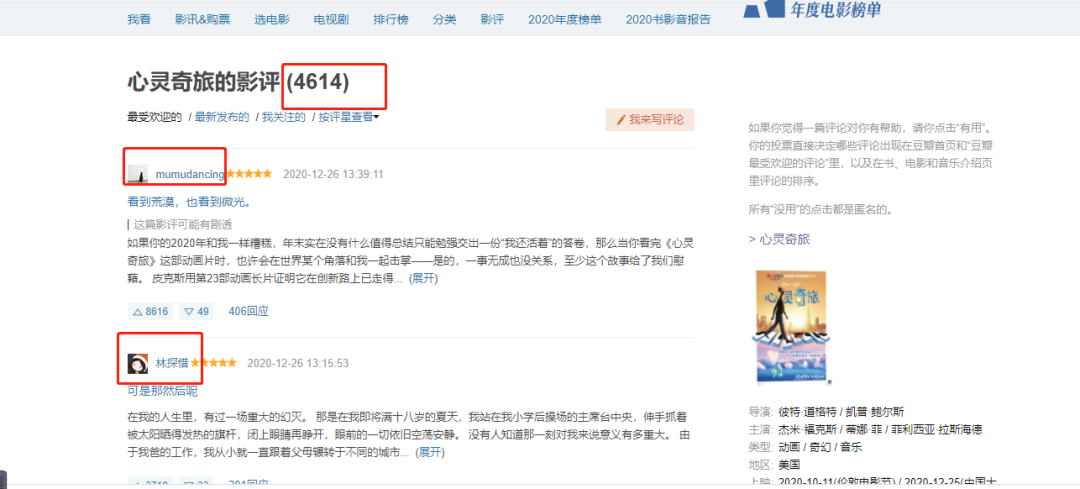
为了获取用户,我选择了其中一部电影的影评,这样可以根据评论的用户去获取其用户名称(后面爬取用户观影记录只需要『用户名称』)。
https://movie.douban.com/subject/24733428/reviews?start=0
url中start参数是页数(page*20,每一页20条数据),因此start=0、20、40...,也就是20的倍数,通过改变start参数值就可以获取这4614条用户的名称。
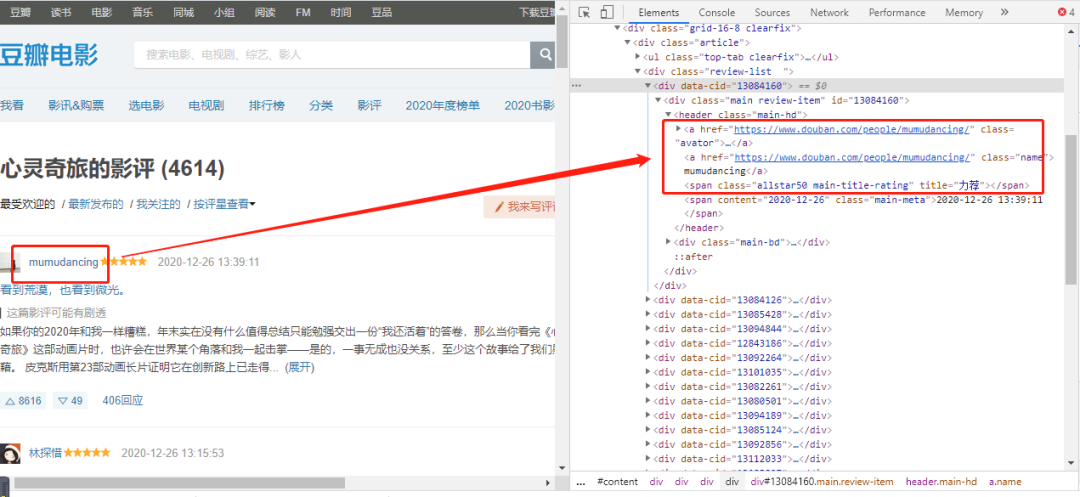
查看网页的标签,可以找到『用户名称』值对应的标签属性。
编程实现
i=0
url = "https://movie.douban.com/subject/24733428/reviews?start=" + str(i * 20)
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="review-list "]/div'):
userid = (item.xpath('.//*[@class="main-hd"]/a[2]/@href'))[0].replace("https://www.douban.com/people/","").replace("/", "")
username = (item.xpath('.//*[@class="main-hd"]/a[2]/text()'))[0]
print(userid)
print(username)
print("-----")

爬取用户的观影记录
上一步爬取到『用户名称』,接着爬取用户观影记录需要用到『用户名称』。
网页分析
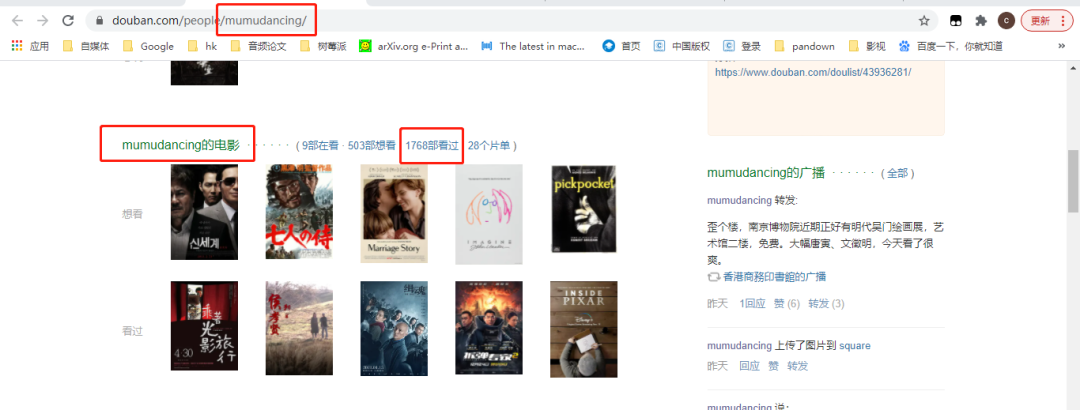
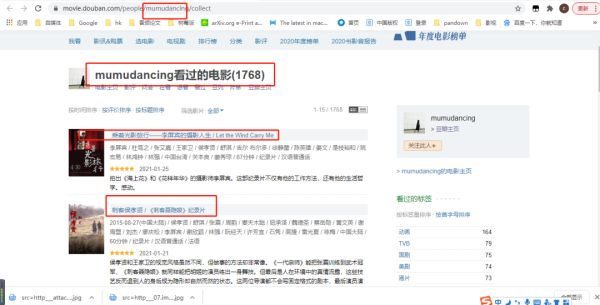
#https://movie.douban.com/people/{用户名称}/collect?start=15sort=timerating=allfilter=allmode=grid
https://movie.douban.com/people/mumudancing/collect?start=15sort=timerating=allfilter=allmode=grid
通过改变『用户名称』,可以获取到不同用户的观影记录。
url中start参数是页数(page*15,每一页15条数据),因此start=0、15、30...,也就是15的倍数,通过改变start参数值就可以获取这1768条观影记录称。
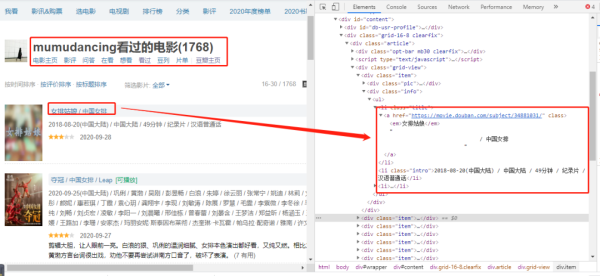
查看网页的标签,可以找到『电影名』值对应的标签属性。
编程实现
url = "https://movie.douban.com/people/mumudancing/collect?start=15sort=timerating=allfilter=allmode=grid"
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="grid-view"]/div[@class="item"]'):
text1 = item.xpath('.//*[@class="title"]/a/em/text()')
text2 = item.xpath('.//*[@class="title"]/a/text()')
text1 = (text1[0]).replace(" ", "")
text2 = (text2[1]).replace(" ", "").replace("\n", "")
print(text1+text1)
print("-----")
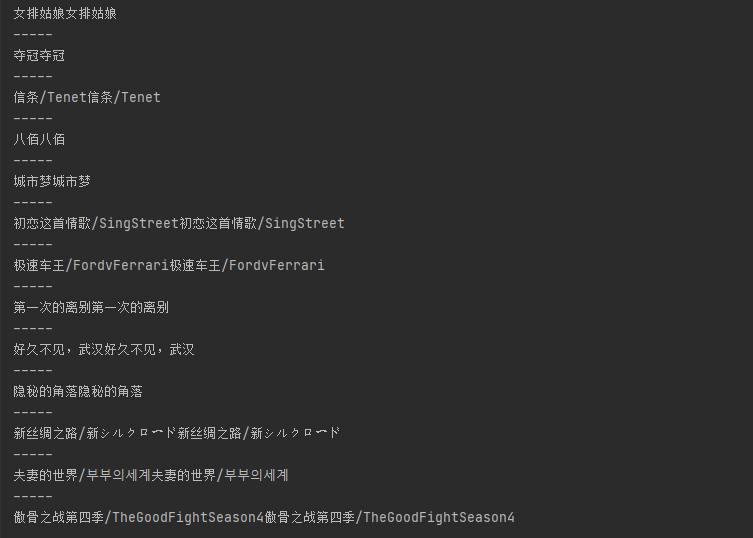
保存到excel
定义表头
# 初始化execl表
def initexcel(filename):
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('sheet1')
workbook.save(str(filename)+'.xls')
##写入表头
value1 = [["用户", "影评"]]
book_name_xls = str(filename)+'.xls'
write_excel_xls_append(book_name_xls, value1)
excel表有两个标题(用户, 影评)
写入excel
# 写入execl
def write_excel_xls_append(path, value):
index = len(value) # 获取需要写入数据的行数
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
new_worksheet.write(i+rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入
new_workbook.save(path) # 保存工作簿
定义了写入excel函数,这样爬起每一页数据时候调用写入函数将数据保存到excel中。
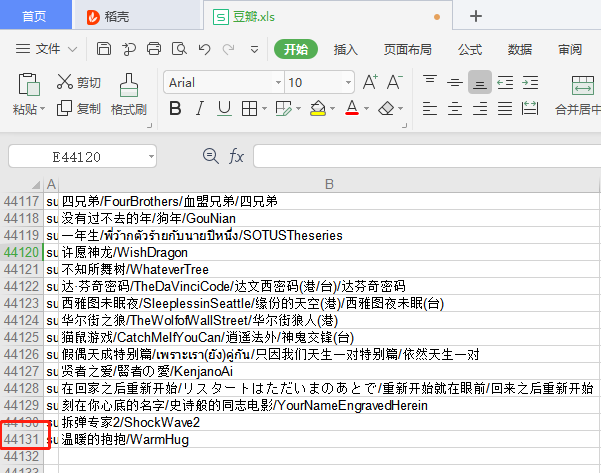
最后采集了44130条数据(原本是4614个用户,每个用户大约有500~1000条数据,预计400万条数据)。但是为了演示分析过程,只爬取每一个用户的前30条观影记录(因为前30条是最新的)。
最后这44130条数据会在下面分享给大家。
三、数据分析挖掘
读取数据集
def read_excel():
# 打开workbook
data = xlrd.open_workbook('豆瓣.xls')
# 获取sheet页
table = data.sheet_by_name('sheet1')
# 已有内容的行数和列数
nrows = table.nrows
datalist=[]
for row in range(nrows):
temp_list = table.row_values(row)
if temp_list[0] != "用户" and temp_list[1] != "影评":
data = []
data.append([str(temp_list[0]), str(temp_list[1])])
datalist.append(data)
return datalist

从豆瓣.xls中读取全部数据放到datalist集合中。
分析1:电影观看次数排行
###分析1:电影观看次数排行
def analysis1():
dict ={}
###从excel读取数据
movie_data = read_excel()
for i in range(0, len(movie_data)):
key = str(movie_data[i][0][1])
try:
dict[key] = dict[key] +1
except:
dict[key]=1
###从小到大排序
dict = sorted(dict.items(), key=lambda kv: (kv[1], kv[0]))
name=[]
num=[]
for i in range(len(dict)-1,len(dict)-16,-1):
print(dict[i])
name.append(((dict[i][0]).split("/"))[0])
num.append(dict[i][1])
plt.figure(figsize=(16, 9))
plt.title('电影观看次数排行(高->低)')
plt.bar(name, num, facecolor='lightskyblue', edgecolor='white')
plt.savefig('电影观看次数排行.png')
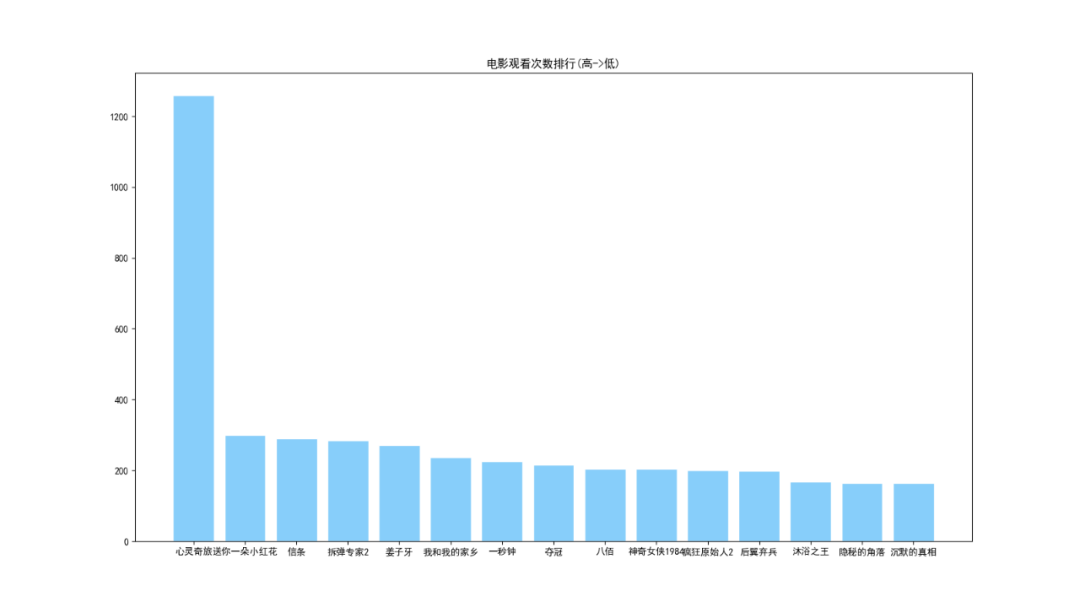
分析由于用户信息来源于 『心灵奇旅』 评论,因此其用户观看量最大。最近的热播电影中,播放量排在第二的是 『送你一朵小红花』,信条和拆弹专家2也紧跟其后。
分析2:用户画像(用户观影相同率最高)
###分析2:用户画像(用户观影相同率最高)
def analysis2():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待画像用户(取第一个)
flag_user=userlist[0]
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判断是否是待画像用户
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待画像用户的所有电影
for j in range(0,len(movies)):
#判断当前用户与待画像用户共同电影个数
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###从小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
#用户名称
username = []
#观看相同电影次数
num = []
for i in range(len(num_dict) - 1, len(num_dict) - 9, -1):
username.append(num_dict[i][0])
num.append(num_dict[i][1])
plt.figure(figsize=(25, 9))
plt.title('用户画像(用户观影相同率最高)')
plt.scatter(username, num, color='r')
plt.plot(username, num)
plt.savefig('用户画像(用户观影相同率最高).png')
分析
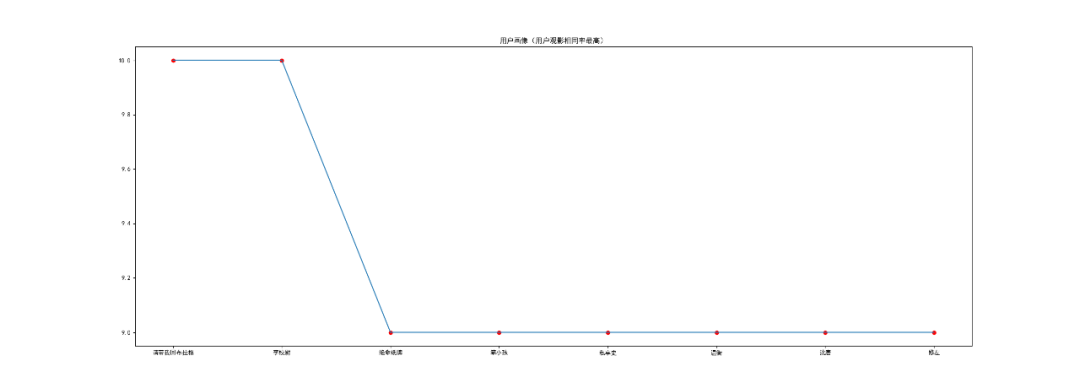
以用户 『mumudancing』 为例进行用户画像
1.从图中可以看出,与用户 『mumudancing』 观影相同率最高的是:“请带我回布拉格”,其次是“李校尉”。
2.用户:'绝命纸牌', '笨小孩', '私享史', '温衡', '沈唐', '修左',的观影相同率****相同。
分析3:用户之间进行电影推荐
###分析3:用户之间进行电影推荐(与其他用户同时被观看过)
def analysis3():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待画像用户(取第2个)
flag_user=userlist[0]
print(flag_user)
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判断是否是待画像用户
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待画像用户的所有电影
for j in range(0,len(movies)):
#判断当前用户与待画像用户共同电影个数
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###从小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
# 去重(用户与观影率最高的用户两者之间重复的电影去掉)
user_movies = dict[flag_user]
new_movies = dict[num_dict[len(num_dict)-1][0]].split(",")
for i in range(0,len(new_movies)):
if new_movies[i] not in user_movies:
print("给用户("+str(flag_user)+")推荐电影:"+str(new_movies[i]))
分析
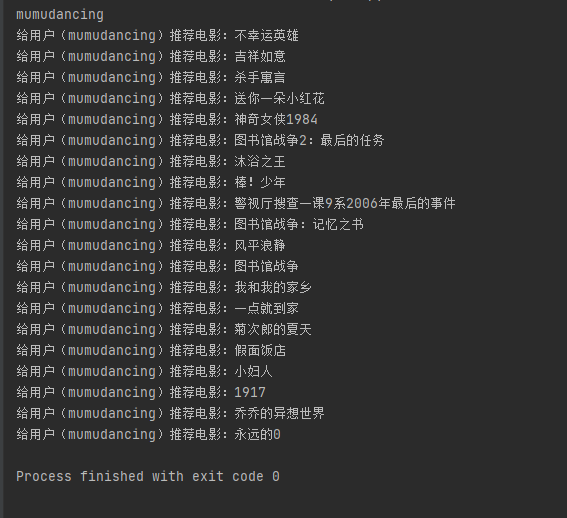
以用户 『mumudancing』 为例,对用户之间进行电影推荐
1.根据与用户 『mumudancing』 观影率最高的用户(A)进行进行关联,然后获取用户(A)的全部观影记录
2.将用户(A)的观影记录推荐给用户 『mumudancing』(去掉两者之间重复的电影)。
分析4:电影之间进行电影推荐
###分析4:电影之间进行电影推荐(与其他电影同时被观看过)
def analysis4():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
movie_list=[]
# 待获取推荐的电影
flag_movie = "送你一朵小红花"
for i in range(0,len(userlist)):
if flag_movie in dict[userlist[i]]:
moives = dict[userlist[i]].split(",")
for j in range(0,len(moives)):
if moives[j] != flag_movie:
movie_list.append(moives[j])
data_dict = {}
for key in movie_list:
data_dict[key] = data_dict.get(key, 0) + 1
###从小到大排序
data_dict = sorted(data_dict.items(), key=lambda kv: (kv[1], kv[0]))
for i in range(len(data_dict) - 1, len(data_dict) -16, -1):
print("根据电影"+str(flag_movie)+"]推荐:"+str(data_dict[i][0]))
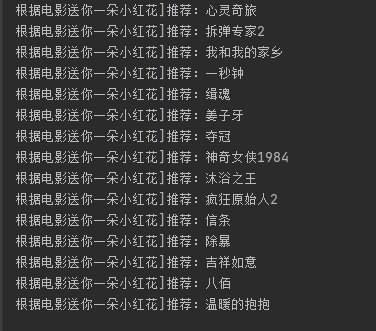
分析
以电影 『送你一朵小红花』 为例,对电影之间进行电影推荐
1.获取观看过 『送你一朵小红花』 的所有用户,接着获取这些用户各自的观影记录。
2.将这些观影记录进行统计汇总(去掉“送你一朵小红花”),然后进行从高到低进行排序,最后可以获取到与电影 『送你一朵小红花』 关联度最高排序的集合。
3.将关联度最高的前15部电影给用户推荐。
四、总结
1.分析爬取豆瓣平台数据思路,并编程实现。
2.对爬取的数据进行分析(电影观看次数排行、用户画像、用户之间进行电影推荐、电影之间进行电影推荐)
到此这篇关于Python爬取用户观影数据并分析用户与电影之间的隐藏信息!的文章就介绍到这了,更多相关Python爬取数据并分析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python爬虫之Appium爬取手机App数据及模拟用户手势
- Python中Cookies导出某站用户数据的方法
- Python编写检测数据库SA用户的方法
- 如何用Python数据可视化来分析用户留存率


 咨 询 客 服
咨 询 客 服