我们今天介绍一个非常适合新手的python自动化小项目,项目虽小,但是五脏俱全。它是一个自动化操作网页浏览器的小应用:打开浏览器,进入百度网页,搜索关键词,最后把搜索结果保存到一个文件里。这个例子非常适合新手学习Python网络自动化,不仅能够了解如何使用Selenium,而且还能知道一些超级好用的小工具。
当然有人把操作网页,然后把网页的关键内容保存下来的应用一律称作网络爬虫,好吧,如果你想这么爬取内容,随你。但是,我更愿意称它为网络机器人。
我今天介绍的项目使用Selenium,Selenium 是支持 web 浏览器自动化的一系列工具和库的综合项目。Selenium 的核心是 WebDriver,这是一个编写指令集的接口,可以在许多浏览器中互换运行。
闲言少叙,硬货安排。
安装 Selenium
可以使用 pip 安装 Python 的 Selenium 库:pip install selenium
(可选项:要执行项目并控制浏览器,需要安装特定于浏览器的 WebDriver 二进制文件。
下载 WebDriver 二进制文件 并放入 系统 PATH 环境变量 中.)
由于本地浏览器版本升级,引起的版本不一致问题,和系统PATH环境变量的设置比较繁琐,所以我使用webdriver_manager,
安装 Install manager:
pip install webdriver-manager
写代码
引入模块:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
首先我们定义一个类Search_Baidu, 它主要用于初始化;定义自动化步骤的方法;结束关闭浏览器。
class Search_Baidu:
def __init__(self):
def search(self, keyword):
def tear_down(self):
接下来我们分别介绍每个方法的实现过程。
def __init__(self): #类构造函数,用于初始化selenium的webdriver
url = 'https://www.baidu.com/' #这里定义访问的网络地址
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
# 这里使用chrome浏览器,而且使用我们刚才安装的webdriver_manager的chrome driver,并赋值上面的浏览器设置options变量
self.browser = webdriver.Chrome(ChromeDriverManager().install(), options=options)
self.wait = WebDriverWait(self.browser, 10) #超时时长为10s,由于自动化需要等待网页控件的加载,所以这里设置一个默认的等待超时,时长为10秒
def tear_down(self):
self.browser.close() #最后,关闭浏览器
接下来是重头戏,写我们操作浏览器的步骤,打开浏览器,进入百度网页,输入搜索关键字:Selenium,等待搜索结果,把搜索结果的题目和网址保存到文件里。
def search(self, keyword):
# 打开百度网页
self.browser.get(self.url)
# 等待搜索框出现,最多等待10秒,否则报超时错误
search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="kw"]')))
# 在搜索框输入搜索的关键字
search_input.send_keys(keyword)
# 回车
search_input.send_keys(Keys.ENTER)
# 等待10秒钟
self.browser.implicitly_wait(10)
# 找到所有的搜索结果
results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
# 遍历所有的搜索结果
with open("search_result.txt","w") as file:
for result in results:
if result.get_attribute("href"):
print(result.get_attribute("text").strip())
# 搜索结果的标题
title = result.get_attribute("text").strip()
# 搜索结果的网址
link = result.get_attribute("href")
# 写入文件
file.write(f"Title: {title}, link is: {link} \n")
点位网页元素
这里头有个关键点,就是如何点位网页元素:
比如:
search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="kw"]')))
还有:
self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
打个比方,快递员通过地址找到你家,给你送快递,这里的XPATH和CSS Selector就是网页元素的地址,那么如何得到呢?
第一个就是Chrome自带的开发者工具,可以快捷键F12,也可以自己在下图中找到:
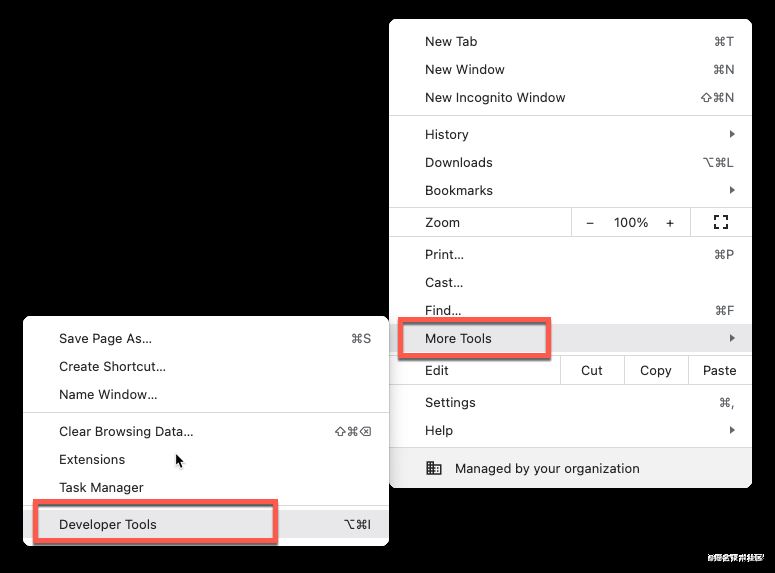
然后在百度搜索框,右键:
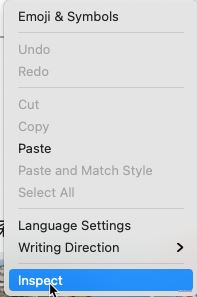
找到输入框的HTML元素,
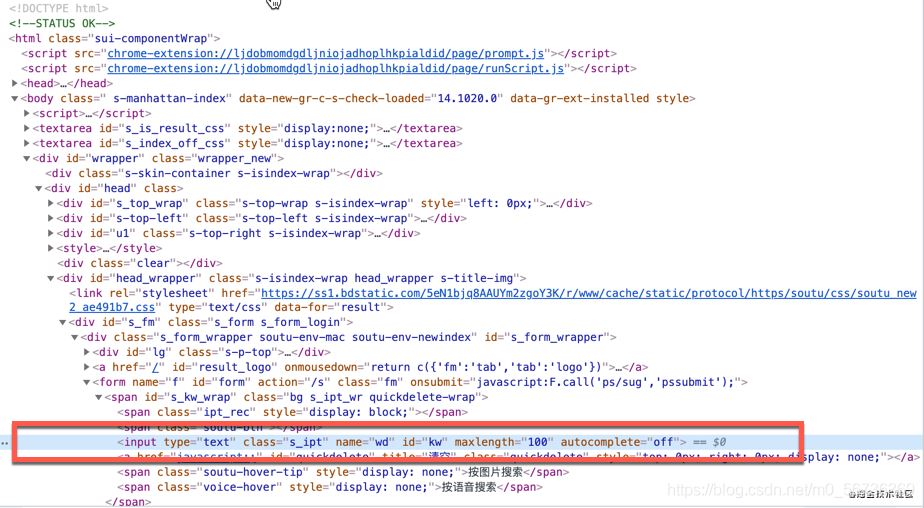
在HTML元素右键,拷贝XPath地址。
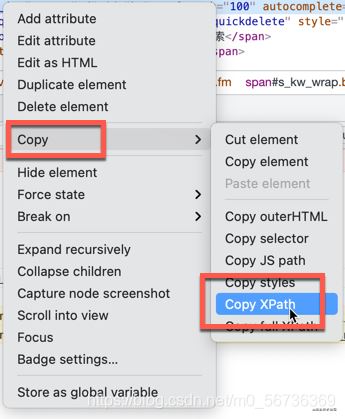
这是比较简单的定位网页元素的方法。接下来我们定位搜索结果元素的时候,就遇到了麻烦,如下图:
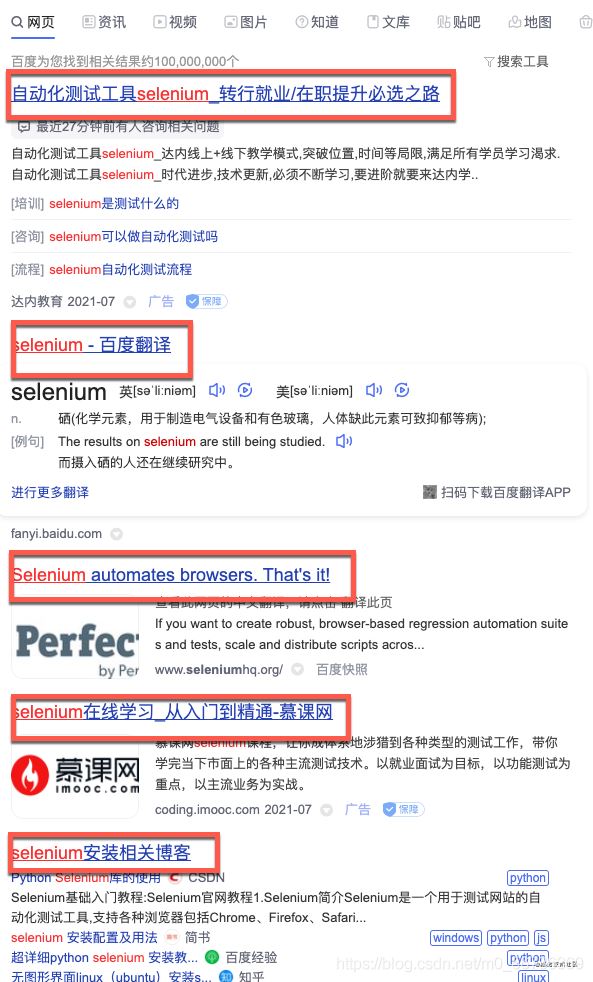
我们不能单独的定位每个元素,而是要找到规律,一次把所有的搜索结果找到,然后返回一个list,我们好遍历这个list,这个怎么实现呢?
接下来,我们请出一大神器:SelectorGadget
SelectorGadget是一个CSS Selector生成器,大家可以在他的官方文档找到具体的使用说明,我这里简单介绍一下:
首先启动SelectorGadget,点击一下图标

浏览器会出现下面的框框:

然后我们在网页用鼠标左键,点击我们要定位的元素

然后页面会变成下面的样子:
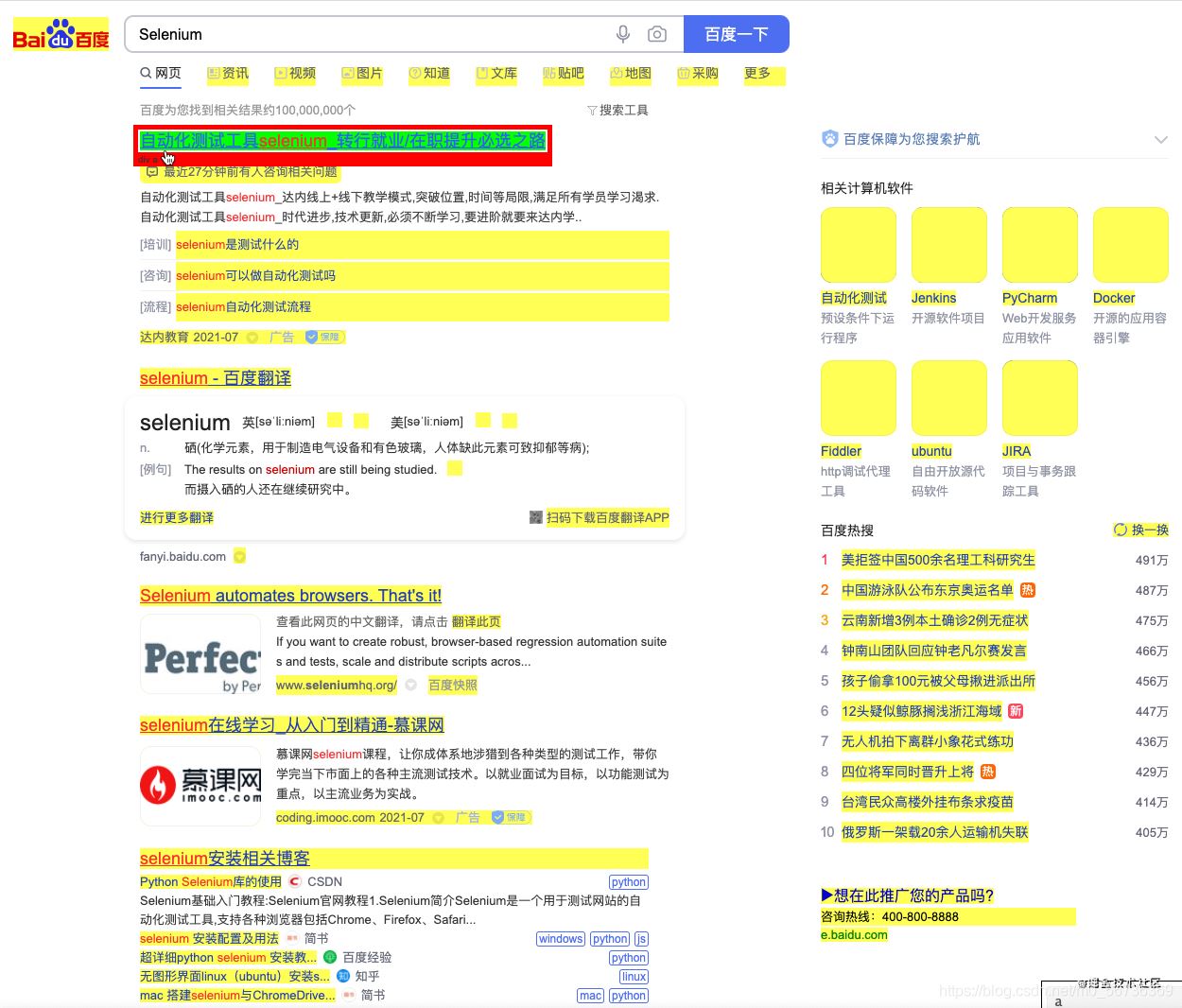
所有黄色的部分说明都被选择了,如果我们不想要的元素,右键点击,使它变为红色,说明它被去掉了。如果没有被选择我们又需要的元素,我们左键选择它,使它变为绿色。最后我们希望选择的页面元素都变成了绿色或者黄色,如下图:

我们就可以拷贝框框里的内容作为CSS Selector了。
通过CSS Selector找到所有的搜索结果。
results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
到此,我们就实现了这么个简单的小应用了,其实selenium就是帮助我们自动操作网页元素,所以我们定位网页元素就是重中之重,希望本文给你带来一点帮助。
下面我附上代码:
from datetime import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
class Search_Baidu:
def __init__(self):
url = 'https://www.baidu.com/'
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
self.browser = webdriver.Chrome(ChromeDriverManager().install(), options=options)
self.wait = WebDriverWait(self.browser, 10) #超时时长为10s
def search(self, keyword):
# 打开百度网页
self.browser.get(self.url)
# 等待搜索框出现,最多等待10秒,否则报超时错误
search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="kw"]')))
# 在搜索框输入搜索的关键字
search_input.send_keys(keyword)
# 回车
search_input.send_keys(Keys.ENTER)
# 等待10秒钟
self.browser.implicitly_wait(10)
# 找到所有的搜索结果
results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
# 遍历所有的搜索结果
with open("search_result.txt","w") as file:
for result in results:
if result.get_attribute("href"):
print(result.get_attribute("text").strip())
# 搜索结果的标题
title = result.get_attribute("text").strip()
# 搜索结果的网址
link = result.get_attribute("href")
# 写入文件
file.write(f"Title: {title}, link is: {link} \n")
def tear_down(self):
self.browser.close()
if __name__ == "__main__":
search = Search_Baidu()
search.search("selenium")
search.tear_down()
到此这篇关于Python使用Selenium自动进行百度搜索的实现的文章就介绍到这了,更多相关Python Selenium自动百度搜索内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 详解Python 使用 selenium 进行自动化测试或者协助日常工作
- Python利用Selenium实现网站自动签到功能
- Selenium+Python自动化脚本环境搭建的全过程
- 利用Python+Selenium破解春秋航空网滑块验证码的实战过程
- python Selenium等待元素出现的具体方法
- Python中Selenium对Cookie的操作方法
- python+opencv+selenium自动化登录邮箱并解决滑动验证的问题
- 用Python selenium实现淘宝抢单机器人
- 教你用Python+selenium搭建自动化测试环境
- Python selenium的这三种等待方式一定要会!
- Python爬虫实战之用selenium爬取某旅游网站
- 教你如何使用Python selenium
- python Web应用程序测试selenium库使用用法详解


 咨 询 客 服
咨 询 客 服