scrapy框架概述:Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
创建项目
由于pycharm不能直接创建scrapy项目,必须通过命令行创建,所以相关操作在pycharm的终端进行:
1、安装scrapy模块:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
2、创建一个scrapy项目:scrapy startproject test_scrapy
4、生成一个爬虫:scrapy genspider itcast "itcast.cn”
5、提取数据:完善spider,使用xpath等方法
6、保存数据:pipeline中保存数据
常用的命令
创建项目:scrapy startproject xxx
进入项目:cd xxx #进入某个文件夹下
创建爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
生成文件:scrapy crawl xxx -o xxx.json (生成某种类型的文件)
运行爬虫:scrapy crawl XXX
列出所有爬虫:scrapy list
获得配置信息:scrapy settings [options]
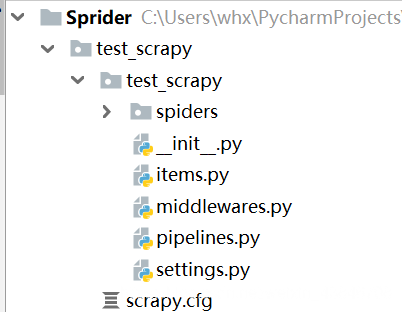
Scrapy项目下文件
scrapy.cfg: 项目的配置文件
test_scrapy/: 该项目的python模块。在此放入代码(核心)
test_scrapy/items.py: 项目中的item文件.(这是创建容器的地方,爬取的信息分别放到不同容器里)
test_scrapy/pipelines.py: 项目中的pipelines文件.
test_scrapy/settings.py: 项目的设置文件.(我用到的设置一下基础参数,比如加个文件头,设置一个编码)
test_scrapy/spiders/: 放置spider代码的目录. (放爬虫的地方)
scrapy框架的整体执行流程
1.spider的yeild将request发送给engine
2.engine对request不做任何处理发送给scheduler
3.scheduler,生成request交给engine
4.engine拿到request,通过middleware发送给downloader
5.downloader在\获取到response之后,又经过middleware发送给engine
6.engine获取到response之后,返回给spider,spider的parse()方法对获取到的response进行处理,解析出items或者requests
7.将解析出来的items或者requests发送给engine
8.engine获取到items或者requests,将items发送给ItemPipeline,将requests发送给scheduler(ps,只有调度器中不存在request时,程序才停止,及时请求失败scrapy也会重新进行请求)
关于yeild函数介绍
简单地讲,yield 的作用就是把一个函数变成一个 generator(生成器),带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,带有yeild的函数遇到yeild的时候就返回一个迭代值,下次迭代时, 代码从 yield 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行, 直到再次遇到 yield。
通俗的讲就是:在一个函数中,程序执行到yield语句的时候,程序暂停,返回yield后面表达式的值,在下一次调用的时候,从yield语句暂停的地方继续执行,如此循环,直到函数执行完。
到此这篇关于python3 scrapy框架的执行流程的文章就介绍到这了,更多相关python3 scrapy框架内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python3 Scrapy爬虫框架ip代理配置的方法
- Python3环境安装Scrapy爬虫框架过程及常见错误
- Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
- Centos7 Python3下安装scrapy的详细步骤
- python3使用scrapy生成csv文件代码示例
- Python3安装Scrapy的方法步骤
- CentOS下安装python3.5+scrapy的方法步骤
- windows10系统中安装python3.x+scrapy教程


 咨 询 客 服
咨 询 客 服