目录
- urllib库
- urllib.request模块
- Request对象
- 1 . 请求头添加
- 2. 操作cookie
- 3. 设置代理
- urllib.parse模块
- urllib.error模块
- urllib.robotparse模块
- 网络库urllib3
urllib库
urllib 是一个用来处理网络请求的python标准库,它包含4个模块。
- urllib.request---请求模块,用于发起网络请求
- urllib.parse---解析模块,用于解析URL
- urllib.error---异常处理模块,用于处理request引起的异常
- urllib.robotparser robots.tx---用于解析robots.txt文件
urllib.request模块
request模块主要负责构造和发起网络请求,并在其中添加Headers,Proxy等。 利用它可以模拟浏览器的请求发起过程。
- 发起网络请求
- 操作cookie
- 添加Headers
- 使用代理
关于urllib.request.urlopen参数的介绍
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urlopen是一个简单发送网络请求的方法。它接收一个字符串格式的url,它会向传入的url发送网络请求,然后返回结果。
先写一个简单的例子:
from urllib import request
response = request.urlopen(url='http://www.httpbin.org/get')
print(response.read().decode())
urlopen默认会发送get请求,当传入data参数时,则会发起POST请求。data参数是字节类型、者类文件对象或可迭代对象。
from urllib import request
response = request.urlopen(url='http://www.httpbin.org/post',
data=b'username=q123password=123')
print(response.read().decode())
还才可以设置超时,如果请求超过设置时间,则抛出异常。timeout没有指定则用系统默认设置,timeout只对,http,https以及ftp连接起作用。它以秒为单位,比如可以设置timeout=0.1 超时时间为0.1秒。
from urllib import request
response = request.urlopen(url='https://www.baidu.com/',timeout=0.1)
Request对象
利用openurl可以发起最基本的请求,但这几个简单的参数不足以构建一个完整的请求,可以利用更强大的Request对象来构建更加完整的请求。
1 . 请求头添加
通过urllib发送的请求会有一个默认的Headers: “User-Agent”:“Python-urllib/3.6”,指明请求是由urllib发送的。所以遇到一些验证User-Agent的网站时,需要我们自定义Headers把自己伪装起来。
from urllib import request
headers ={
'Referer': 'https://www.baidu.com/s?ie=utf-8f=3rsv_bp=1tn=baiduwd=python%20urllib%E5%BA%93oq=python%2520urllib%25E5%25BA%2593rsv_pq=947af0af001c94d0rsv_t=66135egC273yN5Uj589q%2FvA844PvH9087sbPe9ZJsjA8JA10Z2b3%2BtWMpworqlang=cnrsv_enter=0prefixsug=python%2520urllib%25E5%25BA%2593rsp=0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
response = request.Request(url='https://www.baidu.com/',headers=headers)
response = request.urlopen(response)
print(response.read().decode())
2. 操作cookie
在开发爬虫过程中,对cookie的处理非常重要,urllib的cookie的处理如下案例
from urllib import request
from http import cookiejar
# 创建一个cookie对象
cookie = cookiejar.CookieJar()
# 创一个cookie处理器
cookies = request.HTTPCookieProcessor(cookie)
# 以它为参数,创建opener对象
opener = request.build_opener(cookies)
# 使用这个opener 来发请求
res =opener.open('https://www.baidu.com/')
print(cookies.cookiejar)
3. 设置代理
运行爬虫的时候,经常会出现被封IP的情况,这时我们就需要使用ip代理来处理,urllib的IP代理的设置如下:
from urllib import request
url ='http://httpbin.org/ip'
#代理地址
proxy ={'http':'172.0.0.1:3128'}
# 代理处理器
proxies =request.ProxyBasicAuthHandler(proxy)
# 创建opener对象
opener = request.build_opener(proxies)
res =opener.open(url)
print(res.read().decode())
urlib库中的类或或者方法,在发送网络请求后,都会返回一个urllib.response的对象。它包含了请求回来的数据结果。它包含了一些属性和方法,供我们处理返回的结果
- read() 获取响应返回的数据,只能用一次
- readline() 读取一行
- info() 获取响应头信息
- geturl() 获取访问的url
- getcode() 返回状态码
urllib.parse模块
parse.urlencode() 在发送请求的时候,往往会需要传递很多的参数,如果用字符串方法去拼接会比较麻烦,parse.urlencode()方法就是用来拼接url参数的。
from urllib import parse
params = {'wd':'测试', 'code':1, 'height':188}
res = parse.urlencode(params)
print(res)
打印结果为wd=%E6%B5%8B%E8%AF%95code=1height=188
也可以通过parse.parse_qs()方法将它转回字典
print(parse.parse_qs('wd=%E6%B5%8B%E8%AF%95code=1height=188'))
urllib.error模块
error模块主要负责处理异常,如果请求出现错误,我们可以用error模块进行处理 主要包含URLError和HTTPError
URLError:是error异常模块的基类,由request模块产生的异常都可以用这个类来处理
HTTPError:是URLError的子类,主要包含三个属性
- Code:请求的状态码
- reason:错误的原因
- headers:响应的报头
from urllib import request,error
try:
response = request.urlopen("http://pythonsite.com/1111.html")
except error.HTTPError as e:
print(e.reason)
print(e.code)
print(e.headers)
except error.URLError as e:
print(e.reason)
else:
print("reqeust successfully")
urllib.robotparse模块
robotparse模块主要负责处理爬虫协议文件,robots.txt.的解析。
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
网络库urllib3
urllib3是比urllib库更强大的存在,目前已经有许多的原生系统已经开始使用urllib3。
urllib3具有如下优点:
- 支持HTTP和SOCKS代理
- 支持压缩编码
- 100%测试覆盖率
- 具有链接池
- 线程安全
- 客户端SLL/TLS验证
- 协助处理重复请求和HTTP重定位
- 使用multipart编码上传文件
因为urllib3并不是Python的标准库,所以我们使用之前,需要进行下载安装,具体命令如下所示:
pip install urllib3
#或
conda install urllib3
下面,我们来讲解urllib3库的使用方式。
网络请求
GET请求
首先,在我们使用urllib3库进行网络请求时,需创建PoolManager类的实例,该类用于管理线程池。
下面,我们来通过urllib访问百度,并返回查询的结果,示例如下:
import urllib3
http = urllib3.PoolManager()
url = 'http://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = http.request('GET', url, fields={'wd': '机器学习'}, headers=headers)
result = response.data.decode('UTF-8')
print(result)
运行之后,效果如下:

这里,我们通过fields参数指定GET的请求字段。不过,这里先一步讲解了请求头,其实是百度有安全机制,读者可以去掉headers参数试试。会返回百度的安全验证页面。
POST请求
如果需要向服务器提交表单或者比较复杂的数据,就需要使用到POST请求。POST请求比较简单,仅仅只是将请求的第一个参数改为“POST”即可。
示例如下:
import urllib3
http = urllib3.PoolManager()
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = http.request('POST', url, fields={'username': 'name', 'age': '123456'}, headers=headers)
result = response.data.decode('UTF-8')
print(result)
运行之后,返回如下数据:
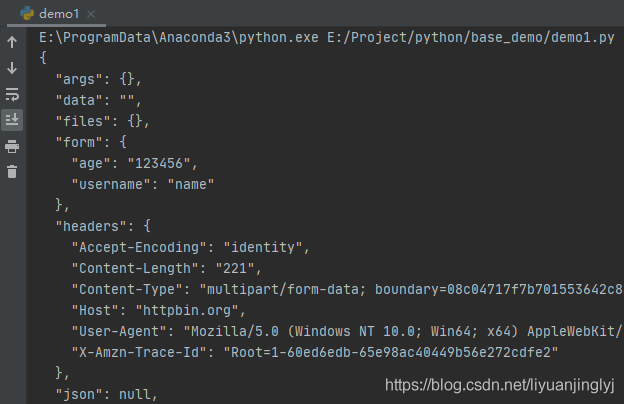
HTTP响应头
使用urllib3库进行网络访问时,其返回的HTTPResponse。默认有一些携带的参数,其中就包括info方法。它能返回响应头数据,示例如下:
import urllib3
http = urllib3.PoolManager()
url = 'http://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = http.request('POST', url, fields={'wd': '机器学习'}, headers=headers)
for key in response.info().keys():
print('key:',response.info()[key])
运行之后,返回的响应数据如下:
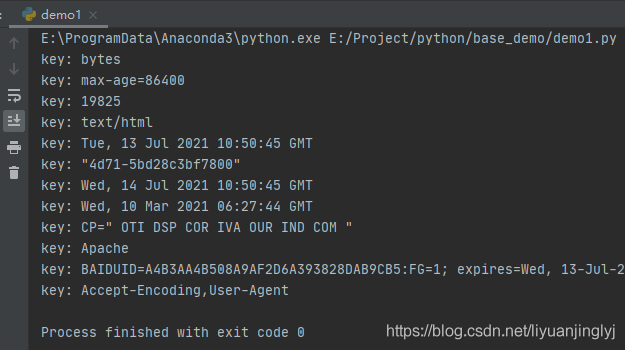
上传文件
首先,我们需要简单的实现一个文件上传的服务器代码,这里我们使用Flask搭建一个简单的服务器Python程序,代码如下:
import flask
import os
UPLOAD_FILE = 'uploads'
app = flask.Flask(__name__)
@app.route('/', methods=['POST'])
def upload_file():
file = flask.request.files['file']
if file:
file.save(os.path.join(UPLOAD_FILE, os.path.basename(file.filename)))
return '文件上传成功'
else:
return '文件上传失败'
if __name__ == '__main__':
app.run()
运行之后,它会一直等待客户端上传文件。
这个时候,我们再来实现urllib3是如何上传文件的,示例如下:
import urllib3
http = urllib3.PoolManager()
with open('1.jpg', 'rb') as f:
fileData = f.read()
url = 'http://127.0.0.1:5000'
response = http.request('POST', url, fields={'file': ('1.jpg', fileData, 'image/jpeg')})
print(response.data.decode('UTF-8'))
默认flask搭建的服务器,其接口为5000,也就是通过127.0.0.1:5000进行访问。运行之后,就会在uploads文件夹下创建一个1.jpg的图片。
同时,控制台会输出文件上传成功,而服务器会返回状态码200。
这里,上传文件就1一个键值对,其中file代表服务器上传文件的字段。值的元组里,fileData为文件的二进制形式,'image/jpeg'代表上传文件的格式(可以省略)。
超时处理
urllib3库其HTTP的底层都是基于Socket实现的,而Socket超时又分为连接超时与读超时。
其中,连接超时表示在连接的过程中,由于服务器的问题或域名弄错了,而导致的无法连接的情况抛出的异常。
读超时表示从服务器读取数据时由于服务器的问题,导致长时间无法正常读取数据而导致的异常。
通常,我们超时的设置有2种,一种是通过http.request(timeout)进行设置,一种是通过PoolManager()连接池进行设置。示例如下:
from urllib3 import *
http = PoolManager(timeout=Timeout(connect=2.0, read=2.0))
with open('1.jpg', 'rb') as f:
fileData = f.read()
url = 'http://127.0.0.1:5000'
try:
response = http.request('POST', url, timeout=Timeout(connect=2.0, read=4.0))
print(response.data.decode('UTF-8'))
except Exception as e:
print(e)
需要注意的是,通过连接池PoolManager进行设置的超时,是全局超时时间,哪怕你后边的请求不设置,也是默认使用的这个超时。如果同时设置了request的超时,那么以request为准。
到此这篇关于Python爬虫中urllib3与urllib的区别是什么的文章就介绍到这了,更多相关Python urllib3 urllib内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 关于python爬虫应用urllib库作用分析
- python爬虫Scrapy框架:媒体管道原理学习分析
- python爬虫Mitmproxy安装使用学习笔记
- Python爬虫和反爬技术过程详解
- python爬虫之Appium爬取手机App数据及模拟用户手势
- 爬虫Python验证码识别入门
- Python爬虫技术
- Python爬虫爬取商品失败处理方法
- Python获取江苏疫情实时数据及爬虫分析
- Python爬虫之Scrapy环境搭建案例教程
- 教你如何利用python3爬虫爬取漫画岛-非人哉漫画
- Python爬虫分析汇总


 咨 询 客 服
咨 询 客 服