需求描述
上周突然接到一个任务,要通过XX网站导出XX年-XX年之间的数据,导出后的文件名就是对应日期,导出后发现,竟然有的文件大小是一样,但文件名又没有重复,所以打开文件看了下,确实重复了,原因暂时不清楚,预测是网站的原因,最后发现大概只有 30% 的数据没有重复。我淦!

啥也不说,首要任务还是把那些没有重复的文件给筛选出来,或是删除重复的文件。文件很多几百个,通过一个个的对比文件去删除估计又要加班,然后突然想到 Python 有个内置的 filecmp 能够貌似是比较文件的,于是乎就有了这篇文章~

撸代码ing
导出的文件都是保存在同一文件夹下的,格式也相同。然后,上网查了下 filecmp.cmp() 的用法。
filecmp.cmp(f1, f2, shallow=True)
f1/f2:待比较的两个文件路径。shallow :默认为True,即只比较os.stat()获取的元数据(创建时间,大小等信息)是否相同,设置为False的话,在对比文件的时候还要比较文件内容。
from pathlib import Path
import filecmp
path_list = [path for path in Path(r'C:\Users\pc\Desktop\test').iterdir() if path.is_file()]
for front in range(len(path_list) - 1):
for later in range(front + 1, len(path_list)):
if filecmp.cmp(path_list[front], path_list[later], shallow=False):
path_list[front].unlink() # 删除文件
break
为了防止代码有问题,我先创建了一个 test 文件夹,在文件夹下手动创建了6个文件,1~5中只有1,2,3,4,5对应的数字内容,第6个为空文件。
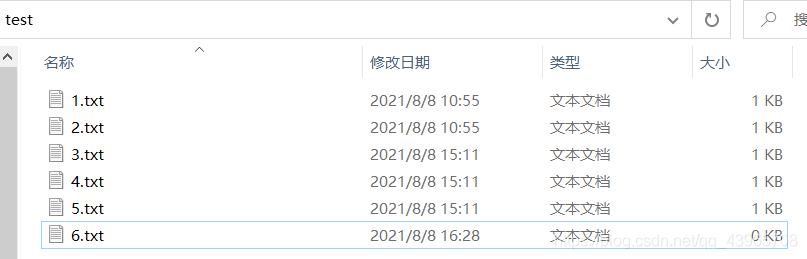
之后再将文件全部复制一份。
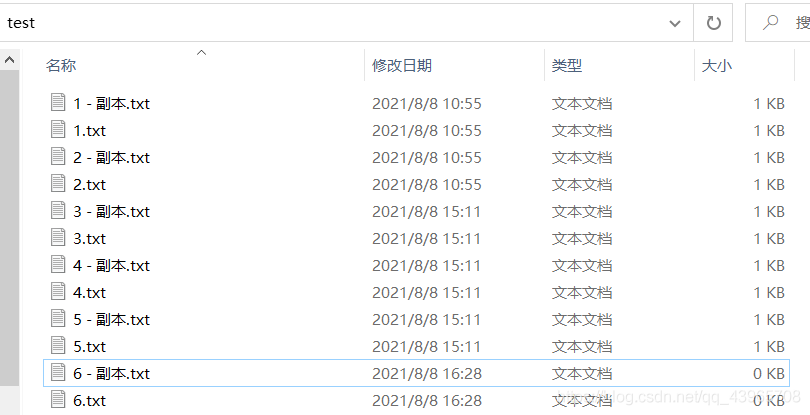
▶️运行效果

到此这篇关于8行代码实现Python文件去重的文章就介绍到这了,更多相关Python文件去重内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python实现MD5进行文件去重的示例代码
- 对python读写文件去重、RE、set的使用详解
- Python实现的txt文件去重功能示例


 咨 询 客 服
咨 询 客 服