Python heapq
heapq 库是 Python 标准库之一,提供了构建小顶堆的方法和一些对小顶堆的基本操作方法(如入堆,出堆等),可以用于实现堆排序算法。
堆是一种基本的数据结构,堆的结构是一棵完全二叉树,并且满足堆积的性质:每个节点(叶节点除外)的值都大于等于(或都小于等于)它的子节点。
堆结构分为大顶堆和小顶堆,在 heapq 中使用的是小顶堆:
- 大顶堆:每个节点(叶节点除外)的值都大于等于其子节点的值,根节点的值是所有节点中最大的。
- 小顶堆:每个节点(叶节点除外)的值都小于等于其子节点的值,根节点的值是所有节点中最小的。
在 heapq 库中,heapq 使用的数据类型是 Python 的基本数据类型 list ,要满足堆积的性质,则在这个列表中,索引 k 的值要小于等于索引 2k+1 的值和索引 2k+2 的值(在完全二叉树中,将数据按广度优先插入,索引为k的节点的子节点索引分别为 2k+1 和 2k+2)。在 heapq 库的源码中也有介绍,可以读一下 heapq 的源码,代码不多。
使用Python实现堆排序可以参考:https://www.jb51.net/article/222484.htm
完全二叉树的特性可以参考:https://www.jb51.net/article/222487.htm
一、使用 heapq 创建堆
import heapq
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heap = []
for num in array:
heapq.heappush(heap, num)
print("array:", array)
print("heap: ", heap)
heapq.heapify(array)
print("array:", array)
运行结果:
array: [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heap: [5, 7, 21, 15, 10, 24, 27, 45, 17, 30, 36, 50]
array: [5, 7, 21, 10, 17, 24, 27, 45, 15, 30, 36, 50]
heapq 中创建堆的方法有两种:
heappush(heap, num),先创建一个空堆,然后将数据一个一个地添加到堆中。每添加一个数据后,heap 都满足小顶堆的特性。
heapify(array),直接将数据列表调整成一个小顶堆(调整的原理参考上面堆排序的文章,heapq库已经实现了)。
两种方法实现的结果会有差异,如上面的代码中,使用 heappush(heap, num) 得到的堆结构如下。
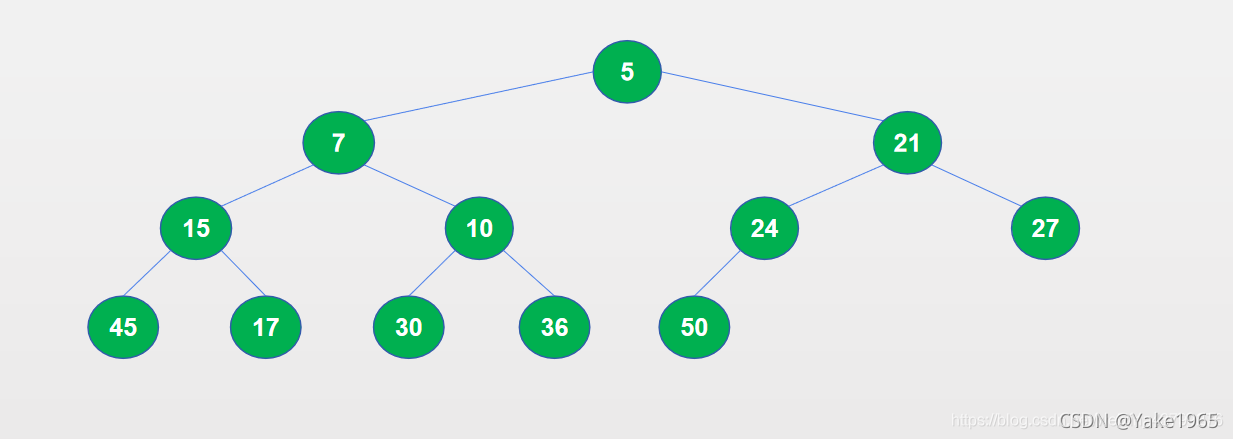
使用heapify(array)得到的堆结构如下。

不过,这两个结果都满足小顶堆的特性,不影响堆的使用(堆只会从堆顶开始取数据,取出数据后会重新调整结构)。
二、使用 heapq 实现堆排序
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heap = []
for num in array:
heapq.heappush(heap, num)
print(heap[0])
# print(heapq.heappop(heap))
heap_sort = [heapq.heappop(heap) for _ in range(len(heap))]
print("heap sort result: ", heap_sort)
运行结果:
5
heap sort result: [5, 7, 10, 15, 17, 21, 24, 27, 30, 36, 45, 50]
先将待排序列表中的数据添加到堆中,构造一个小顶堆,打印第一个数据,可以确认它是最小值。然后依次将堆顶的值取出,添加到一个新的列表中,直到堆中的数据取完,新列表就是排序后的列表。
heappop(heap),将堆顶的数据出堆,并将堆中剩余的数据构造成新的小顶堆。
三、获取堆中的最小值或最大值
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heapq.heapify(array)
print(heapq.nlargest(2, array))
print(heapq.nsmallest(3, array))
运行结果:
[50, 45]
[5, 7, 10]
nlargest(num, heap),从堆中取出 num 个数据,从最大的数据开始取,返回结果是一个列表(即使只取一个数据)。如果 num 大于等于堆中的数据数量,则从大到小取出堆中的所有数据,不会报错,相当于实现了降序排序。
nsmallest(num, heap),从堆中取出 num 个数据,从最小的数据开始取,返回结果是一个列表。
这两个方法除了可以用于堆,也可以直接用于列表,功能一样。
四、使用heapq合并两个有序列表
array_a = [10, 7, 15, 8]
array_b = [17, 3, 8, 20, 13]
array_merge = heapq.merge(sorted(array_a), sorted(array_b))
print("merge result:", list(array_merge))
运行结果:
merge result: [3, 7, 8, 8, 10, 13, 15, 17, 20]
merge(list1, list2),将两个有序的列表合并成一个新的有序列表,返回结果是一个迭代器。这个方法可以用于归并排序。
五、heapq 替换数据的方法
array_c = [10, 7, 15, 8]
heapq.heapify(array_c)
print("before:", array_c)
# 先 push 再 pop
item = heapq.heappushpop(array_c, 5)
print("after: ", array_c)
print(item)
array_d = [10, 7, 15, 8]
heapq.heapify(array_d)
print("before:", array_d)
# 先 pop 再 push
item = heapq.heapreplace(array_d, 5)
print("after: ", array_d)
print(item)
运行结果:
before: [7, 8, 15, 10]
after: [7, 8, 15, 10]
5
before: [7, 8, 15, 10]
after: [5, 8, 15, 10]
7
heappushpop(heap, num),先将 num 添加到堆中,然后将堆顶的数据出堆。
heapreplace(heap, num),先将堆顶的数据出堆,然后将 num 添加到堆中。
两个方法都是即入堆又出堆,只是顺序不一样,可以用于替换堆中的数据。具体的区别可以看代码中的例子。
到此这篇关于Python heapq库案例详解的文章就介绍到这了,更多相关Python heapq库内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python数据库如何连接SQLite详解
- python实现图像处理之PiL依赖库的案例应用详解
- Python 数据科学 Matplotlib图库详解
- python中的tkinter库弹窗messagebox详解
- python数据可视化plt库实例详解
- 一篇文章带你详细了解python中一些好用的库


 咨 询 客 服
咨 询 客 服