在学习python的时候,一定会遇到网站内容是通过 ajax动态请求、异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据。
至于读取静态网页内容的方式,有兴趣的可以查看本文内容。
这里我们以爬取淘宝评论为例子讲解一下如何去做到的。
这里主要分为了四步:
一 获取淘宝评论时,ajax请求链接(url)
二 获取该ajax请求返回的json数据
三 使用python解析json数据
四 保存解析的结果
步骤一:
获取淘宝评论时,ajax请求链接(url)这里我使用的是Chrome浏览器来完成的。打开淘宝链接,在搜索框中搜索一个商品,比如“鞋子”,这里我们选择第一项商品。

然后跳转到了一个新的网页中。在这里由于我们需要爬取用户的评论,所以我们点击累计评价。

然后我们就可以看到用户对该商品的评价了,这时我们在网页中右击选择审查元素(或者直接使用F12打开)并且选中Network选项,如图所示:
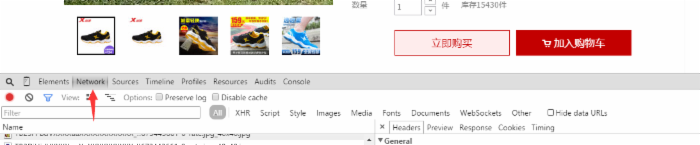
我们在用户评论中,翻到底部 点击下一页或者第二页,我们在Network中看到动态添加了几项,我们选择开头为list_detail_rate.htm?itemId=35648967399的一项。

然后点击该选项,我们可以在右边选项框中看到有关该链接的信息,我们要复制Request URL中的链接内容。

我们在浏览器的地址栏中输入刚才我们获得url链接,打开后我们会发现页面返回的是我们所需要的数据,不过显得很乱,因为这是json数据。

二 获取该ajax请求返回的json数据
下一步,我们就要获取url中的json数据了。我所使用的python编辑器是pycharm,下面看一下python代码:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399spuId=226460655sellerId=1809124267ℴ=3currentPage=1append=0content=1tagId=posi=picture=ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3Disg=82B6A3A1ED52A6996BCA2111C9DAAEE6_ksTS=1440490222698_2142callback=jsonp2143' #这里的url比较长
content=requests.get(url).content
print content #打印出来的内容就是我们之前在网页中获取到的json数据。包括用户的评论。
这里的content就是我们所需要的json数据,下一步就需要我们解析这些个json数据了。
三 使用python解析json数据
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
import json
import re
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399spuId=226460655sellerId=1809124267ℴ=3currentPage=1append=0content=1tagId=posi=picture=ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3Disg=82B6A3A1ED52A6996BCA2111C9DAAEE6_ksTS=1440490222698_2142callback=jsonp2143'
cont=requests.get(url).content
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}')
content=rex.findall(cont)[0]
con=json.loads(content,"gbk")
count=len(con['rateDetail']['rateList'])
for i in xrange(count):
print con['rateDetail']['rateList'][i]['appendComment']['content']

解析:
这里需要导入所要的包,re为正则表达式需要的包,解析json数据需要import json
cont=requests.get(url).content #获取网页中json数据
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}') #正则表达式去除cont数据中多余的部分,是数据成为真正的json格式的数据{“a”:”b”,”c”:”d”}
con=json.loads(content,”gbk”) 使用json的loads函数 将content内容转化为json库函数可以处理的数据格式,”gbk”为数据的编码方式,由于win系统默认为gbk
count=len(con[‘rateDetail'][‘rateList']) #获取用户评论的个数(这里只是当前页的)
for i in xrange(count):
print con[‘rateDetail'][‘rateList'][i][‘appendComment']
#循环遍历用户的评论 并输出(也可以根据需求保存数据,可以查看第四部分)
这里的难点是在杂乱的json数据中查找用户评论的路径
四 保存解析的结果
这里用户可以将用户的评论信息保存到本地,如保存为csv格式。
以上就是本文的全部所述,希望大家喜欢。
您可能感兴趣的文章:- python+selenium定时爬取丁香园的新型冠状病毒数据并制作出类似的地图(部署到云服务器)
- python 爬取疫情数据的源码
- 用python爬取历史天气数据的方法示例
- Python大数据之从网页上爬取数据的方法详解
- python多线程+代理池爬取天天基金网、股票数据过程解析
- Python如何爬取实时变化的WebSocket数据的方法
- 实例讲解Python爬取网页数据
- Python爬取数据并写入MySQL数据库的实例
- python爬虫爬取网页表格数据
- python爬取网站数据保存使用的方法
- 如何用python爬取微博热搜数据并保存


 咨 询 客 服
咨 询 客 服