做日志分析工作的经常需要跟成千上万的日志条目打交道,为了在庞大的数据量中找到特定模式的数据,常常需要编写很多复杂的正则表达式。例如枚举出日志文件中不包含某个特定字符串的条目,找出不以某个特定字符串打头的条目,等等。
使用否定式前瞻
正则表达式中有前瞻(Lookahead)和后顾(Lookbehind)的概念,这两个术语非常形象的描述了正则引擎的匹配行为。需要注意一点,正则表达式中的前和后和我们一般理解的前后有点不同。一段文本,我们一般习惯把文本开头的方向称作“前面”,文本末尾方向称为“后面”。但是对于正则表达式引擎来说,因为它是从文本头部向尾部开始解析的(可以通过正则选项控制解析方向),因此对于文本尾部方向,称为“前”,因为这个时候,正则引擎还没走到那块,而对文本头部方向,则称为“后”,因为正则引擎已经走过了那一块地方。如下图所示:
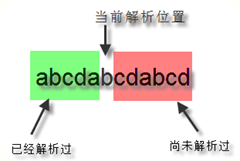
所谓的前瞻就是在正则表达式匹配到某个字符的时候,往“尚未解析过的文本”预先看一下,看是不是符合/不符合匹配模式,而后顾,就是在正则引擎已经匹配过的文本看看是不是符合/不符合匹配模式。符合和不符合特定匹配模式我们又称为肯定式匹配和否定式匹配。
现代高级正则表达式引擎一般都支持都支持前瞻,对于后顾支持并不是很广泛,因此我们这里采用否定式前瞻来实现我们的需求。
实现
测试数据:
复制代码 代码如下:
2009-07-07 04:38:44 127.0.0.1 GET /robots.txt
2009-07-07 04:38:44 127.0.0.1 GET /posts/robotfile.txt
2009-07-08 04:38:44 127.0.0.1 GET /
例如上面这几条简单的日志条目,我们想实现两个目标:
1. 把8号的数据过滤掉
2. 把那些不包含robots.txt字符串的条目给找出来(只要Url中包含robots.txt的都给过滤掉)。
前瞻的语法是:
(?!匹配模式)我们先来实现第一个目标——匹配不以特定字符串开头的条目。
这里我们因为要排除一段连续的字符串,因此匹配模式非常简单,就是2009-07-08。实现如下:
复制代码 代码如下:
^(?!2009-07-08).*?$
用Expresso我们可以看到结果确实过滤掉8号的数据。
接下来,我们来实现第二个目标——排除包含特定字符串的条目。
按照我们上面写法,我照葫芦画瓢了一下:
复制代码 代码如下:
^.*?(?!robots\.txt).*?$
这段正则用大白话描述就是:开头任意字符,然后后面不要跟着robots.txt连续字符串,然后再跟着任意个字符,字符串结尾。
运行测试,结果发现:
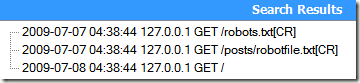
没有达到我们想要的效果。这是为什么呢?我们给上面的正则表达式加上两个捕获分组调试一下:
复制代码 代码如下:
^(.*?)(?!robots\.txt)(.*?)$
测试结果:
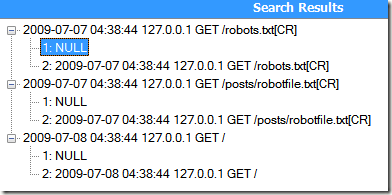
我们看到,第一个分组啥都没有匹配到,而第二个分组却匹配了整个字符串。再回过头来好好分析一下刚才那个正则表达式。实际上,当正则引擎解析到A区域的时候,就已经开始执行B区域的前瞻工作。这个时候发现当A区域为Null的时候匹配成功——.*本来就允许匹配空字符,前瞻条件又满足,A区域后面紧跟着的是“2009”字符串,而并不是robots。因此整个匹配过程成功匹配到所有条目。
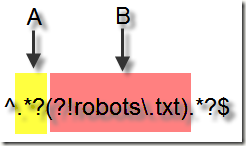
分析出原因之后我们对上述的正则进行修正,将.*?移入前瞻表达式,如下:
复制代码 代码如下:
^(?!.*?robots).*$
测试结果:
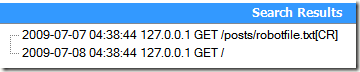
完成
php中用正则实现不包括某个字符串的实现方法
preg_match("/^((?!abc).)*$/is", $str);
完整代码示例
复制代码 代码如下:
$str = "dfadfadf765577abc55fd";
$pattern_url = "/^((?!abc).)*$/is";
if (preg_match($pattern_url, $str))
{
echo "不含有abc!";
}
else
{
echo "含有abc!";
}
结果为:false,含有abc!
同时匹配,包含字符串 "abc",而且不包含字符串 "xyz"的正则表达式:
preg_match("/(abc)[^((?!xyz).)*$]/is", $str);
该方法有效,本人使用方法如下:
(?:(?!\/div>).|\n)*? //匹配不含/div>的一个字符串
但最终使用中结果是发现,该方法效率极其低下,在处理非常短文字(要匹配该正则式的相同部分的有十几个字,或者最多几十个)时间可以考虑使用,但当用于大篇幅文章解析或多处需要改种匹配时间应不使用,考虑用其他方法替代(如:先解析出要匹配该段正则式的文字,然后验证其中是否存在某段文字),正则表达式对于匹配不含特定字符串的文字段时并不是非常有效的方法.
您可能感兴趣的文章:- 正则表达式匹配不包含某些字符串的技巧
- JS正则表达式提取字符串中所有汉字的脚本
- 正则表达式截取字符串的方法技巧
- 利用正则表达式将字符串分组示例代码


 咨 询 客 服
咨 询 客 服