
|
alnum |
文字数字字符 |
|
alpha |
文字字符 |
|
blank |
空白字符 |
|
cntrl |
控制字符 |
|
digit |
数字字符 |
|
graph |
图形字符 |
|
lower |
小写文字字符 |
|
|
图形或空格字符 |
|
punct |
标点字符 |
|
space |
空格、制表符、新行、和回车 |
|
upper |
大写文字字符 |
|
xdigit |
十六进制数字字符 |
它们代表在ctype(3)手册页面中定义的字符类。特定地区可能会提供其他类名。字符类不得用作范围的端点。
mysql> SELECT 'justalnums' REGEXP '[[:alnum:]]+';
-> 1
mysql> SELECT '!!' REGEXP '[[:alnum:]]+';
-> 0
[[::]], [[:>:]]
这些标记表示word边界。它们分别与word的开始和结束匹配。word是一系列字字符,其前面和后面均没有字字符。字字符是alnum类中的字母数字字符或下划线(_)。
mysql> SELECT 'a word a' REGEXP '[[::]]word[[:>:]]';
-> 1
mysql> SELECT 'a xword a' REGEXP '[[::]]word[[:>:]]';
-> 0
要想在正则表达式中使用特殊字符的文字实例,应在其前面加上2个反斜杠“\”字符。MySQL解析程序负责解释其中一个,正则表达式库负责解释另一个。例如,要想与包含特殊字符“+”的字符串“1+2”匹配,在下面的正则表达式中,只有最后一个是正确的:
mysql> SELECT '1+2' REGEXP '1+2';
-> 0
mysql> SELECT '1+2' REGEXP '1\+2';
-> 0
mysql> SELECT '1+2' REGEXP '1\\+2';
-> 1
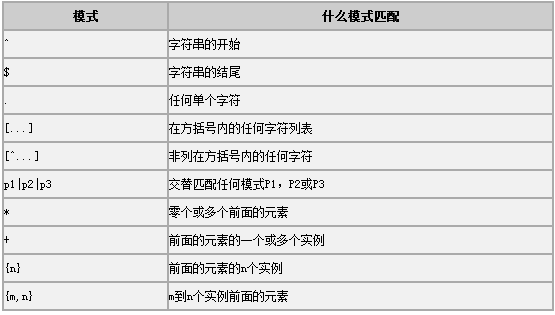
以下是可用于随REGEXP操作符的表的模式。
应用示例,查找用户表中Email格式错误的用户记录:
SELECT *
FROM users
WHERE email NOT REGEXP '^[A-Z0-9._%-]+@[A-Z0-9.-]+.[A-Z]{2,4}$'
MySQL数据库中正则表达式的语法,主要包括各种符号的含义。
(^)字符
匹配字符串的开始位置,如“^a”表示以字母a开头的字符串。
mysql> select 'xxxyyy' regexp '^xx'; +-----------------------+ | 'xxxyyy' regexp '^xx' | +-----------------------+ | 1 | +-----------------------+ 1 row in set (0.00 sec)
查询xxxyyy字符串中是否以xx开头,结果值为1,表示值为true,满足条件。
($)字符
匹配字符串的结束位置,如“X^”表示以字母X结尾的字符串。
(.)字符
这个字符就是英文下的点,它匹配任何一个字符,包括回车、换行等。
(*)字符
星号匹配0个或多个字符,在它之前必须有内容。如:
mysql> select 'xxxyyy' regexp 'x*';
这个SQL语句,正则匹配为true。
(+)字符
加号匹配1个或多个字符,在它之前也必须有内容。加号跟星号的用法类似,只是星号允许出现0次,加号则必须至少出现一次。
(?)字符
问号匹配0次或1次。
实例:
现在根据上面的表,可以装置各种不同类型的SQL查询以满足要求。在这里列出一些理解。考虑我们有一个表为person_tbl和有一个字段名为名称:
查询找到所有的名字以'st'开头
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^st';
查询找到所有的名字以'ok'结尾
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'ok$';
查询找到所有的名字包函'mar'的字符串
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'mar';
查询找到所有名称以元音开始和'ok'结束 的
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
一个正则表达式中的可以使用以下保留字
^
所匹配的字符串以后面的字符串开头
mysql> select "fonfo" REGEXP "^fo$"; -> 0(表示不匹配) mysql> select "fofo" REGEXP "^fo"; -> 1(表示匹配)
$
所匹配的字符串以前面的字符串结尾
mysql> select "fono" REGEXP "^fono$"; -> 1(表示匹配) mysql> select "fono" REGEXP "^fo$"; -> 0(表示不匹配) .
匹配任何字符(包括新行)
mysql> select "fofo" REGEXP "^f.*"; -> 1(表示匹配) mysql> select "fonfo" REGEXP "^f.*"; -> 1(表示匹配)
a*
匹配任意多个a(包括空串)
mysql> select "Ban" REGEXP "^Ba*n"; -> 1(表示匹配) mysql> select "Baaan" REGEXP "^Ba*n"; -> 1(表示匹配) mysql> select "Bn" REGEXP "^Ba*n"; -> 1(表示匹配)
a+
匹配任意多个a(不包括空串)
mysql> select "Ban" REGEXP "^Ba+n"; -> 1(表示匹配) mysql> select "Bn" REGEXP "^Ba+n"; -> 0(表示不匹配)
a?
匹配一个或零个a
mysql> select "Bn" REGEXP "^Ba?n"; -> 1(表示匹配) mysql> select "Ban" REGEXP "^Ba?n"; -> 1(表示匹配) mysql> select "Baan" REGEXP "^Ba?n"; -> 0(表示不匹配)
de|abc
匹配de或abc
mysql> select "pi" REGEXP "pi|apa"; -> 1(表示匹配) mysql> select "axe" REGEXP "pi|apa"; -> 0(表示不匹配) mysql> select "apa" REGEXP "pi|apa"; -> 1(表示匹配) mysql> select "apa" REGEXP "^(pi|apa)$"; -> 1(表示匹配) mysql> select "pi" REGEXP "^(pi|apa)$"; -> 1(表示匹配) mysql> select "pix" REGEXP "^(pi|apa)$"; -> 0(表示不匹配)
(abc)*
匹配任意多个abc(包括空串)
mysql> select "pi" REGEXP "^(pi)*$"; -> 1(表示匹配) mysql> select "pip" REGEXP "^(pi)*$"; -> 0(表示不匹配) mysql> select "pipi" REGEXP "^(pi)*$"; -> 1(表示匹配)
{1}
{2,3}
这是一个更全面的方法,它可以实现前面好几种保留字的功能
a*
可以写成a{0,}
a+
可以写成a{1,}
a?
可以写成a{0,1}
在{}内只有一个整型参数i,表示字符只能出现i次;在{}内有一个整型参数i,后面跟一个“,”,表示字符可以出现i次或i次以上;在{}内只有一个整型参数i,后面跟一个“,”,再跟一个整型参数j,表示字符只能出现i次以上,j次以下(包括i次和j次)。其中的整型参数必须大于等于0,小于等于 RE_DUP_MAX(默认是255)。 如果有两个参数,第二个必须大于等于第一个
[a-dX]
匹配“a”、“b”、“c”、“d”或“X”
[^a-dX]
匹配除“a”、“b”、“c”、“d”、“X”以外的任何字符。
“[”、“]”必须成对使用
mysql> select "aXbc" REGEXP "[a-dXYZ]"; -> 1(表示匹配) mysql> select "aXbc" REGEXP "^[a-dXYZ]$"; -> 0(表示不匹配) mysql> select "aXbc" REGEXP "^[a-dXYZ]+$"; -> 1(表示匹配) mysql> select "aXbc" REGEXP "^[^a-dXYZ]+$"; -> 0(表示不匹配) mysql> select "gheis" REGEXP "^[^a-dXYZ]+$"; -> 1(表示匹配) mysql> select "gheisa" REGEXP "^[^a-dXYZ]+$"; -> 0(表示不匹配)

 咨 询 客 服
咨 询 客 服