7月15日,被《福布斯》杂志誉为“大数据运动的里程碑”的全球顶级大数据会议Strata Data Conference在京召开。第四范式先知平台架构师陈迪豪受邀出席大会,并分享了云深度学习平台的架构与实践经验。
作为第四范式先知平台架构师,陈迪豪活跃于Open stack、Kubernetes、TensorFlow等开源社区,实现了Cloud Machine Learning 云深度学习平台,对如何进行云深度学习平台架构有着深厚积累。本次演讲中,他介绍了什么是云深度学习?在经过实践后,应该如何重新定义云深度学习?以及第四范式在这方面的应用和实践。以下文章按照现场演讲实录整理。
定义云深度学习平台
什么是云深度学习?随着机器学习的发展,单机运行的机器学习任务存在缺少资源隔离、无法动态伸缩等问题,因此要用到基于云计算的基础架构办事。云机器学习平台并不是一个全新的概念,Google、微软、亚马逊等都有相应的办事,这里列举几个比较典型的例子。
第一个是Google Cloud Machine Learning Engine,它底层托管在Google Cloud上,上层封装了Training、Prediction、Model Service等机器学习应用的抽象,再上层支持了Google官方的TensorFlow开源框架。亚马逊也推出了Amzon machine learning平台,它基于AWS的Iaas架构,在Iaas上提供两种差别的办事,别离是可以运行MXNet等框架的EC2虚拟机办事,以及各种图象、语音、自然语言处理的SaaS API。此外,微软提供了Azure Machine Learning Studio办事,底层也是基于本身可伸缩、可拓展的Microsoft Azure Cloud办事,上层提供了拖拽式的更易用的Studio工具,再上面支持微软官方的CNTK等框架,除此之外微软还有各种感知办事、图象处理等SaaS API,这些办事都是跑在Scalable的云基础平台上面。
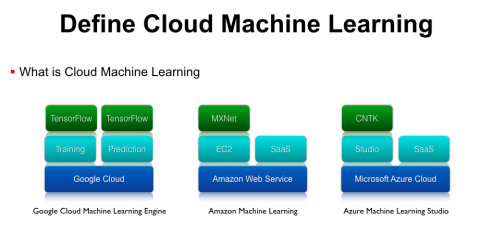
以上这些都是业界比较成熟的云深度学习平台,而在真实的企业环境中,我们为什么还需要实现Cloud Machine Learning办事呢?首先国外的基础设施并不必然是国内企业可以直接使用的,而如果只是当地安置了TensorFlow,那也只能在裸机上进行训练,当地默认没有资源隔离,如果同时跑两个训练任务就需要本身去解决资源冲突的问题。因为没有资源隔离,所以也做不了资源共享,即使你有多节点的计算集群资源,也需要人工的约定才能保证任务不会冲突,无法充分利用资源共享带来的便当。此外,开源的机器学习框架没有集群级另外编排功能,例如你想用分布式TensorFlow时,需要手动在多台办事器上启动进程,没有自动的Failover和Scalling。因此,很多企业已经有机器学习的业务,但因为缺少Cloud Machine Learning平台,仍会有安排、办理、集群调度等问题。

那么如何实现Cloud Machine Learning平台呢?我们对云深度学习办事做了一个分层,第一层是平台层,类似于Google cloud、Azure、AWS这样的IaaS层,企业内部也可以使用一些开源的方案,如容器编排工具Kubernetes或者虚拟机办理工具OpenStack。有了这层之后,我们还需要支持机器学习相关的功能,例如Training、Prediction、模型上线、模型迭代更新等,我们在Machine Learning Layer层对这些功能进行抽象,实现了对应的API接口。最上面是模型应用层,就可以基于一些开源的机器学习类库,如TensorFlow、MXNet等。

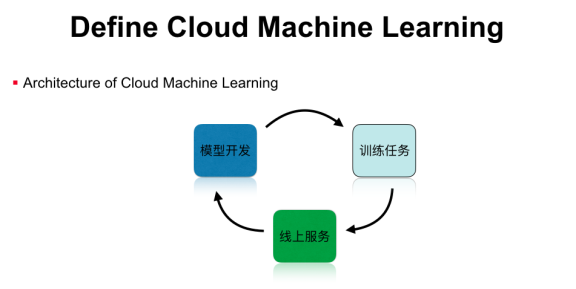
整个Cloud Machine learning运行在可伸缩的云办事上,包行了模型开发、模型训练,以及模型办事等功能,形成一个完整的机器学习工作流。但这并不是一个闭环,我们在实践中发现,线上的机器学习模型是有时效性的,例如新闻保举模型就需要及时更新热点新闻的样本特征,这时就需要把闭环打通,把线上的预测结果加入到线下的训练任务里,然后通过在线学习或者模型升级,实现完整的机器学习闭环,这些都是单机版的机器学习平台所不能实现的。
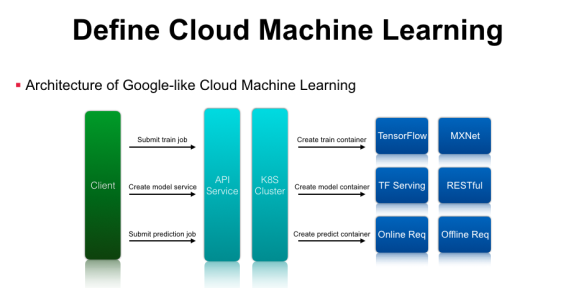
打造云深度学习平台主要包罗以下几个组件:首先是客户端拜候的API Service,作为办事提供方,我们需要提供尺度的RESTful API办事,后端可以对接一个Kubernetes集群、OpenStack集群、甚至是自研的资源办理系统。客户端请求到API办事后,平台需要解析机器学习任务的参数,通过Kubernetes或者OpenStack来创建任务,调度到后端真正执行运算的集群资源中。如果是训练任务,可以通过起一个训练任务的Container,里面预装了TensorFlow或MXNet运行环境,通过这几层抽象就可以将单机版的TensorFlow训练任务提交到由Kubernetes办理的计算集群中运行。在模型训练结束后,系统可以导出模型对应的文件,通过请求云深度学习平台的API办事,最终翻译成Kubernetes可以理解的资源配置请求,在集群中启动TensorFlow Serving等办事。除此之外,,在Google Cloud-ML最新的API里多了一个Prediction功能,预测时既可以启动在线Service,也可以启动离线的Prediction的任务,平台只需要创建对应的Prediction的容器来做Inference和生存预测结果即可 。通过这种简单的封装,就可以实现类似Google Cloud-ML的基础架构了。


 咨 询 客 服
咨 询 客 服