强大号码库资源任选,方便,快捷,快速开通。
咨询热线:400-1100-266
前言:本文是“Dedecms采集功能的使用方法 --- 图片集“的第二节,在前一节的基础上,将会对新增采集节点中的第二步:“设置字段获取规则”部分做一个简单的介绍。为了与前文保持一致,本文将延续使用前文的章节标记。
上接第一节。
2.1新增采集节点:第二步设置内容字段获取规则
单击“保存信息并进入下一步设置”后,便可进入“新增采集节点:第二步设置内容字段获取规则”页面,如(图21)所示,

(此图片来源于网络,如有侵权,请联系删除! )
图21-设置内容字段获取规则
在预览网址处,系统将会自动指定一篇文章作为示范页面,如有特殊需要可自行更改。打开示范页面,经观察可发现页面中含有分页,如(图22)所示,

(此图片来源于网络,如有侵权,请联系删除! )
图22-分页
下面来设置分页部分的匹配规则。
具体操作步骤:
(a)在页面的源代码中,找到分页代码的开始部分和结束部分,如(图23)所示,

(此图片来源于网络,如有侵权,请联系删除! )
图23-分页代码
(b)经过观察可知,分页代码位于“<div class=”show_pages”>“和”</div>”之间。因此,在”内容分页导航所在的区域匹配规则“中,应填写”<div class=”show_pages”>[内容]</div> “。对于分页代码的样式,一共有三种可供选择,这里应选择第一种” 全部列出的分页列表”。填写后,如(图24)所示

(此图片来源于网络,如有侵权,请联系删除! )
图24-设置后的网页内容获取规则
对于“固定采集项目”中的“内容摘要、关键字和缩略图“三个部分,系统会用正则进行自动匹配,仅需配置过滤内容即可。下面主要介绍如何获取“文章标题、文章作者、文章来源、发布时间和文章内容”的采集规则以及简单的过滤规则。
2.1.1 获取文章标题的采集规则
首先,打开“预览网址“的页面并单击右键,选择”查看源代码“,找到文章标题” 高清壁纸(非原创作品)“,如(图25)所示,

(此图片来源于网络,如有侵权,请联系删除! )
图25-在源代码中的文章标题
这里的文章标题处在”<h1 class=“font14 b blink”></h1>”之间,因此这里应该填写”<h1 class=“ font14 b blink”>[内容]</h1>”作为文章标题的匹配规则。对于所包含的<img src=”/images/digest1.gif alt=”推荐的欣赏”>”可根据需要选择保留或者是过滤掉。如果希望把这张图片过滤掉,需要在过滤规则中填写:“{dede:trim replace=''}<img([^>]*)>{/dede:trim}”。填写后,如(图26)所示,
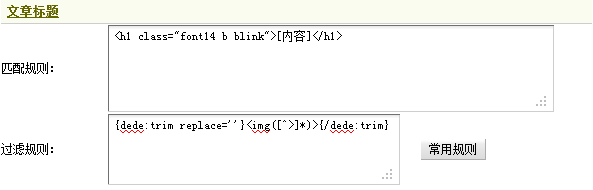
(此图片来源于网络,如有侵权,请联系删除! )
图26-文章标题的采集规则
2.1.2 获取文章作者的采集规则
经过查找源代码和对比原文,可发现本文没有涉及到原文作者。这里选择不填写。
2.1.3 获取文章来源的采集规则
这里把页面中的上传者作为文章来源,如图(27)所示,
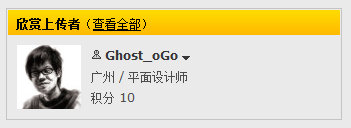
(此图片来源于网络,如有侵权,请联系删除! )
图27-上传者的信息
查看源代码,并找到相应的部分,如(图28)所示,
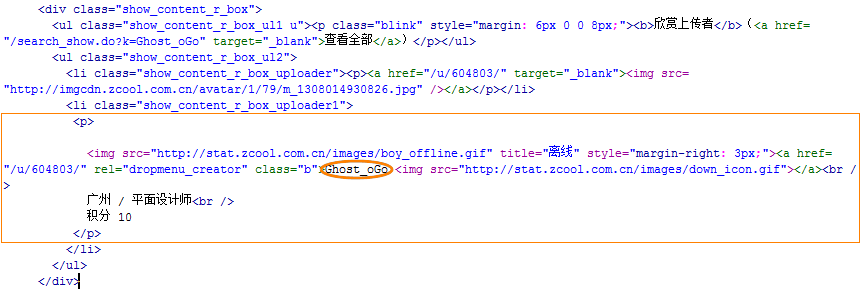
(此图片来源于网络,如有侵权,请联系删除! )
图28-源代码中上传者的信息
从图28中,可发现上传者的名字介于“<li class="show_content_r_box_uploader1"><p>“和“</p>”之间,因此这里应填写“<li class="show_content_r_box_uploader1"><p>[内容]</p>”作为文章来源的采集规则。虽然,选定的采集规则能采集到上传者的名字,但是同时也包含了所不希望采集到的图片和链接,下面通过设置过滤规则把它们过滤掉。首先,过滤掉链接,这里使用“{dede:trim replace=''}<a([^>]*)>{/dede:trim}{dede:trim replace=’’}</a>{/dede:trim}”;其次,使用“{dede:trim replace=''}<img([^>]*)>{/dede:trim}”过滤掉图片。填写后,如图29所示,

(此图片来源于网络,如有侵权,请联系删除! )
图29-文章来源的采集规则
2.1.4 获取文章发布时间的采集规则
回到图23,可发现有“17小时前”,由此可见,这里采集数字17就可以了。采集规则为“<span class=”bh”>[内容]小时前</span>”。这里不需要使用过滤规则。填写后,如图30所示,
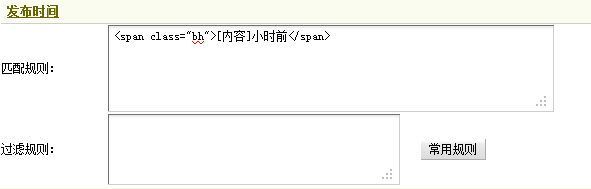
(此图片来源于网络,如有侵权,请联系删除! )
图30-文章发布时间的采集规则
2.1.5 获取图片集合以及图集内容的采集规则
这个部分是编写采集规则的重点,也是难点。需要特别注意。
图片集合:如果把采集的匹配规则填写在这里的话,系统就会把所采集到的图片,以图集的形式保存起来,注意这里只采集图片。
图集内容:在显示图集的时候,所需显示的说明性文字或者图片。
具体操作步骤:
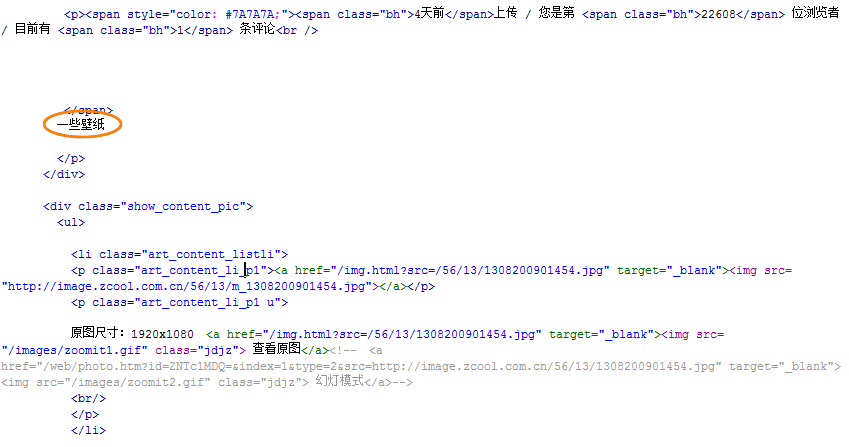
(a)在打开的内容页面的源代码中,找到内容的开始部分“一些壁纸”,如图31所示,
(此图片来源于网络,如有侵权,请联系删除! )
图31-内容的开始部分
分析一下这个源代码可知,以下两点:
(1)“一些壁纸”是这个图集的内容,因此可以把“条评论<br/>”作为匹配图集内容的开始部分。但是这样采集到的内容会包含有</span>,应该在过滤规则中使用“{dede:trim replace=""}</span>{/dede:trim}”过滤掉。
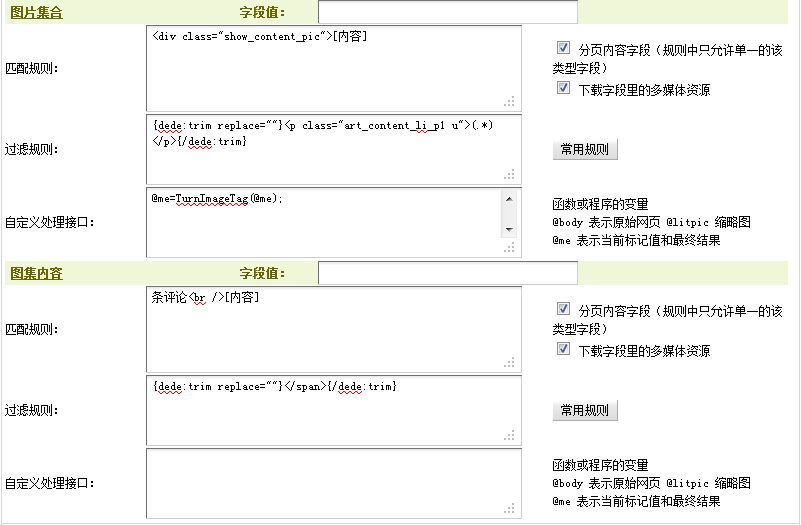
(2)“<div class=”show_content_pic”><ul>”可作为匹配图片集合的开始部分,而且每一个图片及其相关信息都是在“<li class=”art_content_listli”>”和”</li>”之间的。注意到这段代码中有两个地方都出现了<img>,通过对比原文可发现,”<img src=”/images/zoomit1.gif” class=”jdjz”>”是一个图标的源代码,这里是不应该被采集到的。为了过滤掉这个图标,需要在匹配规则中填写“{dede:trim replace=""}<p class="art_content_li_p1 u">(.*)</p>{/dede:trim}”。
填写后,如(图32)所示,
(此图片来源于网络,如有侵权,请联系删除! )
图32-开始部分的匹配规则及其过滤规则
(b)找到图集内容的结束部分,因为涉及到分页部分,所以应该选取分页结束的位置,如图33所示,

(此图片来源于网络,如有侵权,请联系删除! )
图33-图集内容的结束部分
很明显,这里应选取“<li style="text-align:center;"><script type="text/javascript”>”作为图片集合和图集内容的结束部分。填写完成后,如(图34)所示,

(此图片来源于网络,如有侵权,请联系删除! )
图34-结束部分的匹配规则及其过滤规则
到这里,“新增采集节点:第二步设置内容字段获取规则”,就设置完成了。来看一下整个配置页面,如(图35)所示,

(此图片来源于网络,如有侵权,请联系删除! )
图35-设置后的新增采集节点:第二步设置内容字段获取规则
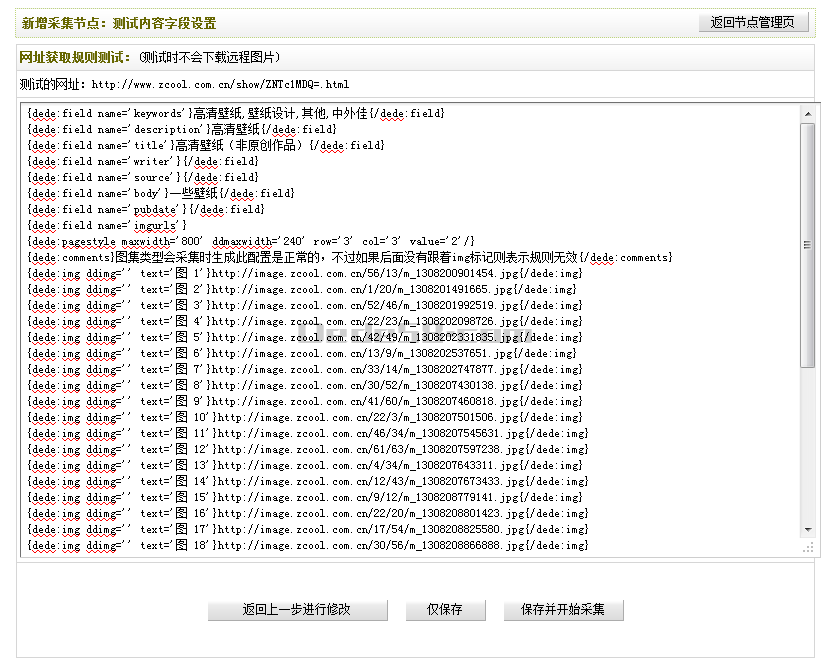
检查无误后,单击“保存并测试”。如果之前设置正确,单击后,将会进入“新增采集节点:测试内容字段设置”页面并看到相应的文章内容。如(图36)所示,
(此图片来源于网络,如有侵权,请联系删除! )
图36-新增采集节点:测试内容字段设置
确定正确无误后,如果单击“仅保存”,系统将会提示“成功保存配置“并返回”采集节点管理“界面;如果单击“保存并开始采集“,将会进入”采集指定节点“界面。否则,请单击“返回上一步进行修改”。
关于第二节的介绍就到这里。下面进入第三节。。。

时间:9:00-21:00 (节假日不休)
版权所有:巨人网络(扬州)科技有限公司
总部地址:江苏省信息产业基地11号楼四层
《增值电信业务经营许可证》 苏B2-20120278

